自动摘要: 1.模型思路 1.输入为一个模型点云数据的集合,随机采样后(保证输入数据大小都一致),形状表示为N*3(N代表这个模型的点的数量,3代表(x,y,z)) 2.输入数据先于一个**T ……..
1.模型思路
- 输入为一个模型点云数据的集合,随机采样后(保证输入数据大小都一致),形状表示为N*3(N代表这个模型的点的数量,3代表(x,y,z))
- 输入数据先于一个T-Net(transform网络结构)学习到的转换矩阵对其,保证了模型对特定空间的旋转不变性(反映了点云的性质)
- 通过多次MLP(多层的全连接的前馈网络)对点云数据进行特征提取,再用一个T-Net对特征对齐
- 注:
- MLP在网络中逐层前馈(从输入层到隐藏层到输出层,逐层计算结果,即所谓前馈)
- BP叫误差逆传播优化算法
- 狭隘地认为:神经网络=MLP,那么,BP神经网络=BP-MLP(通过BP算法进行优化得到的MLP网络)
- 注:
- 在特征的各维度上执行最大池化来得到最终全局特征。
- 对于分类问题,将全局特征通过MLP来预测最后的分类分数(针对全局)
- 对于分割任务,将全局特征于对齐后的特征的局部特征进行
串联拼接,在通多MLP的到每个数据点的分类结果(针对点的)
1.1问题
1.针对密集稠密点云,用MLP提取特征可能效果不太好,shapenet,modelnet数据集都是稀疏点云!答:所以大家常用pointNet++,pointNet++在分类问题上使用pointnet+FCN,在分割问题上用encoder-decoder模型2.为什么要使用conv1d,而不是用conv3d,conv2d?答:conv1d只是对一个点的坐标进行卷积,完全没有考虑其他点的信息,如conv2d还要考虑临近像素信息。而我常常在NLP任务中看到conv1d:
- 比如一个系统有三个词[‘我’,’打’,’你’],那么’我’=[1,0,0],’打’=[0,1,0],’你’=[0,1,0],’我打’=[1,1,0]等等
- 每个词向量大小为3,对应在点云就表示(x,y,z)
- 样本假设如上有4个,对应一个模型点云有2500个点
- PointNet中所有卷积核的大小都是1
- 也就是每层卷积都是对单个点样本进行处理,并没有考虑别的点
- 而在MLP卷积核一般大于1,假设卷积核大小为4,假设输出结果为4*1,那么这个卷积过程中,每个输出值都是考虑4个词向量,即代表可以提取词与词 的关系特征
- 而在pointNet却无法实现,原因:词之间向量关系可以确定,但点云存储时相邻点并不代表在空间上时相邻的,因为点云无序性
- 所以卷积过程中无法考虑周围点的信息会严重减低网络的能力,效果好只是样本过于简单,pontNet++尝试利用CNN方式解决局部信息
补充:在tensorflow版,用的conv2d代替conv1d,以获得cudnn优化
3.网络的maxpool层用torch.max(x, 2, keepdim=True)[0]**表示,而不用nn.MaxPool1d?**答:经过代码验证:
1 | import torch |
可以认为一个样本(模型)映射为一个特征
- 针对使用max,而不是 maxpool1d 是因为计算速度更快?
- 答:时间太短,不一定是这个问题,我个人认为他只想从2500–>1,没有像maxpool1d(2500)这种操作,如果要使用maxpool一般是循序渐进池化,而不是这样使用,我认为作者在化繁为简
4.全局特征与局部特征如何串联拼接的?****答:
1 | torch.cat([x, pointfeat], 1) |
2.网络结构
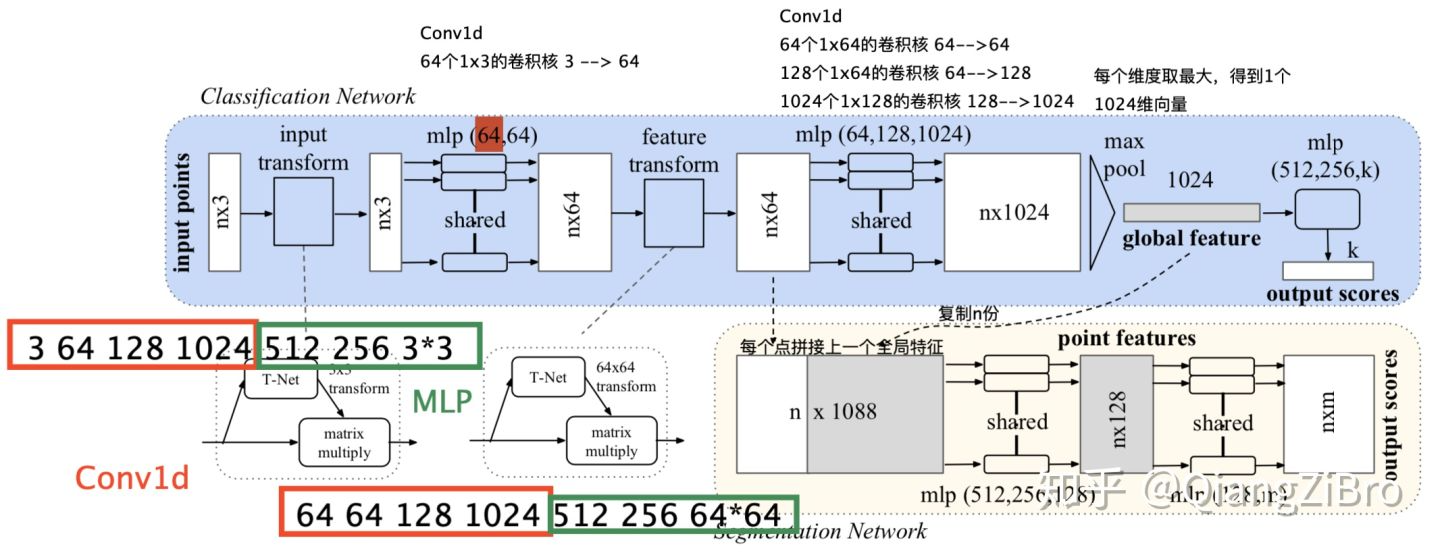
2.1各个部件解释:
T-Net(transform):
- 第一次,T-Net 3x3,对输入点云进行对齐;
- 第二次,T-Net 64*64,对64维特征进行对齐;
MLP:
- 用于提取点云特征,使用共享权重的卷积
max pool:
- **汇总所有点云的信息,进行最大池化,得到点云的全局 信息 **
分割:
- 局部和全局信息串联结构(concate,语义分割)
- 交叉熵+(原图(就是图中feature transform的输出)的转置的Frobenius范数的平均值) 0.001*(这里就是论文中增加了正则损失(regularization loss,权重0.001)以约束输出尽量为正交矩阵。)
- 注:

- 注:
分类:
- 交叉熵
2.2步骤
- 将输入的点云数据作为nx3x1单通道图图像(或者认为是序列文本)—
- 接三次卷积和一次池化后,再reshape为1024个节点,然后接两层全连接
- 网络除最后一层外都使用了ReLU激活函数和批标准化。
实际中:T矩阵的参数初始化使用单位矩阵(np.eye(K)), 参数会随着整个网络的训练进行更新,并不是提前单独训练的。T-Net对特征进行对齐,保证了模型的对特定空间转换的不变性。注:
1 | #STNkd下forward |
3.CONV1D拓展
1.一维卷积基本信息:
- 卷积核有两个维度:高:H,宽W;H=C(通道),W=kernel size;
- 输出通道:一个卷积核一个通道,多通道就要多个卷积核
- 参数:批量大小N,通道数C,序列数L
2.例子:点云的点(x,y,z),通道数为3,假设我们有2500个点,则L=2500。
3.kernel size = 1****卷积核为1,则w=1:
1 | input=torch.randn(1,3,1)#输入一个点 |
1 | #卷积核大小 |
1 | #提取第一个卷积核 |
4.kernel =2
1 | input=torch.randn(1,3,1)#输入一个点 |
如果input=torch.randn(1,3,2)则可以继续
4.T-Net拓展
1.第一个T-Net:
- 是一个mini-pointNet(_MLP+_max pooling+2*FC)
- 输入是未经过网络处理的原始点云
- 输出是3x3的旋转矩阵(每次迭代矩阵初始值为单位阵作为偏差加入),感觉是在做一定扰动
2.第二个T-Net:
- 结构与第一个相同
- 输入是特征提取后的点云
- 输出是64x64的旋转矩阵(同样每次迭代矩阵初始值为单位阵作为偏差加入)
理解:不变性体现:从T-Net获得旋转矩阵trans_feat ,然后与样本相乘,获得新的输出,通过控制最后的loss来对变换矩阵进行调整,pointnet并不关心最后真正做了什么变换,只要有利于最后的结果都可以。第一次是对空间中点云调整,第二次是对特征层面点云进行变换!对应代码:
1 | if self.feature_transform: |
https://kevinzakka.github.io/2017/01/18/stn-part2/

