自动摘要: |版本号|作者|发布日期|修订| ||||| |V1.0.0|@叶子扬||初始版| |V1.1 ……..
| 版本号 | 作者 | 发布日期 | 修订 |
|---|---|---|---|
| V1.0.0 | @叶子扬 | 初始版 | |
| V1.1.0 | @Sindre Yang(sindre) | 2023年3月17日 | 整理并修正 |
🔖 参考资料
- 本次迭代周期中没有涉及到值得一提的参考资料
🛒 项目环境
- python 3.7.6
- pytorch 1.6.0
- numpy 1.18.1
- pandas 1.1.3
- vedo 2020.4.2
- scikit-learn 0.22.1
- visdom 0.1.8.9 (optional; for step3)
- thundersvm (optional; for step6)
- pygco (0.0.1) (optional; for step6)
🛒 项目流程
数据前处理
- 文件:
stl_To_vtp.py- 采用21组上下颌降采样的stl模型数据和txt标签数据,导出为vtp格式
- 将对颌牙打上相同的标签原数据命名为
Sample_0{n}_d.vtp,做镜像处理的数据命名为'Sample_0{n}_d.vtp'.format(j+1000) - 保存在
_./models/rerrangge_文件夹中
- 文件:
数据增强
- 文件:
step1_augmentation.py- 为了增加训练数据集,通过旋转、放大、平移每个网格原数据和镜像处理后的网格数据,命名为
stl_To_vtp.py和A{0}_Sample_0{1}_d.vtp'.format(i_aug, i_sample+1000) - 保存在_./models/augmentation_vtk_data_ ”文件夹
- 为了增加训练数据集,通过旋转、放大、平移每个网格原数据和镜像处理后的网格数据,命名为
- 文件:
生成训练集和验证集
- 文件:
step2_get_list.py- 定义变量
num_augmentation和num_samples,使用21组数据中的16组80%为训练集、20%为验证集、测试集来自训练集 - 测试集、训练集、验证集分别被分为六个csv文件,存储训练、验证网格的相对地址和测试网格的ID
combine_train.py便于训练,合并六个训练子集
- 定义变量
- 文件:
训练数据
- 文件:
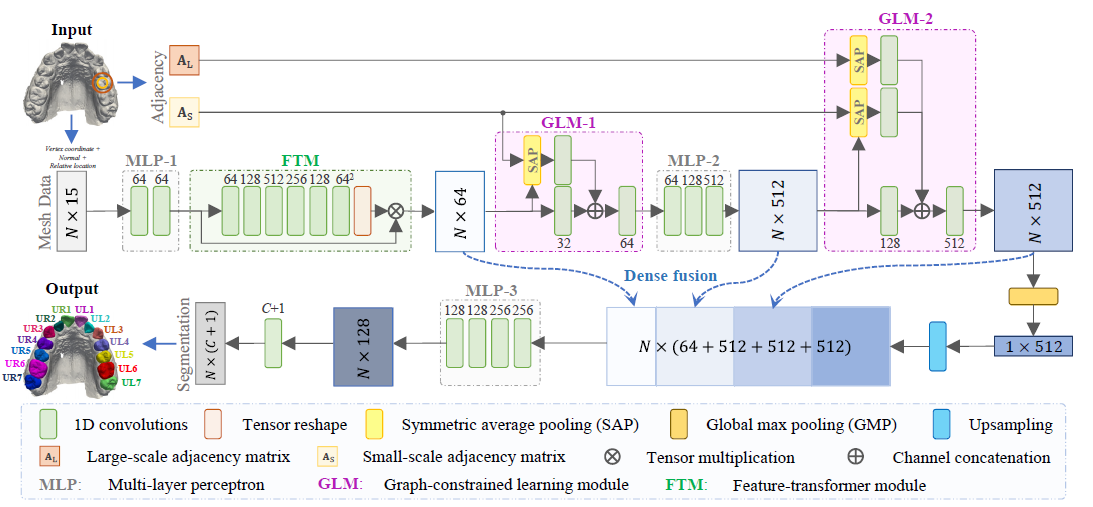
step3_training.py- 15个类(14颗牙齿和牙龈),特征数为15个包括三个顶点坐标(9)、法向量(3),相对位置向量(3)
- 准备输入特征和进一步增强的数据以及计算相邻矩阵(AS和AL)都是由
Mesh_dataset.py进行的 - 为了进一步扩充数据集,在“
_./models/augmentation_vtk_data_中的原数据中选择所有牙齿面片并随机选择一些牙龈面片形成 6,000 个面片训练。 - 输出
losses_metrics_vs_epoch.csv得到loss,DSC,SEN,PPV,val_loss,val_DSC,val_SEN,val_PPV指标
- 文件:
step3_1_continous_training.py- 作者在
_./models_文件夹中提供了两个经过训练的模型(一个上部和一个下部)和训练曲线dsc_vs_epoch.pngloss_vs_epoch.pngppv_vs_epoch.pngsen_vs_epoch.pngMeshSegNet_Man_15_classes_72samples_lr1e-2_best.zipMeshSegNet_Max_15_classes_72samples_lr1e-2_best.zip
- 作者在
- 文件:
可以选择自己的训练模型或者是作者的来继续训练输出
losses_metrics_vs_epoch.csv得到loss,DSC,SEN,PPV,val_loss,val_DSC,val_SEN,val_PPV指标
模型测试
- 文件:
step4_test.py
- 文件:
模型推理
- 文件:
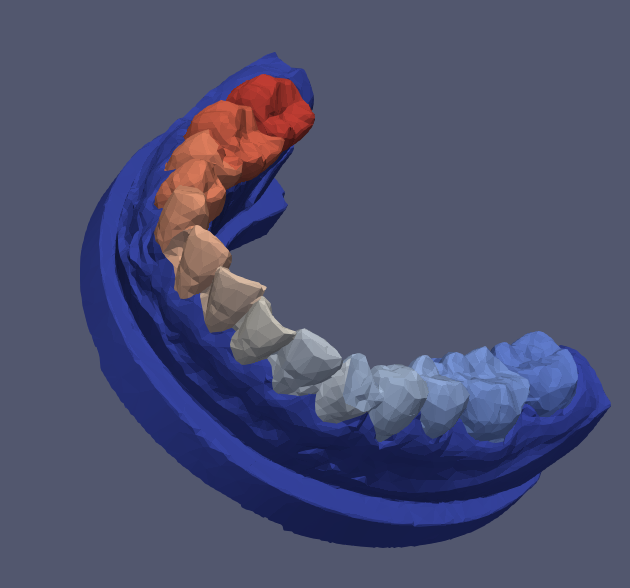
step5_predict.py- 得到
Example_d_predicted.vtp
- 得到
- 文件:
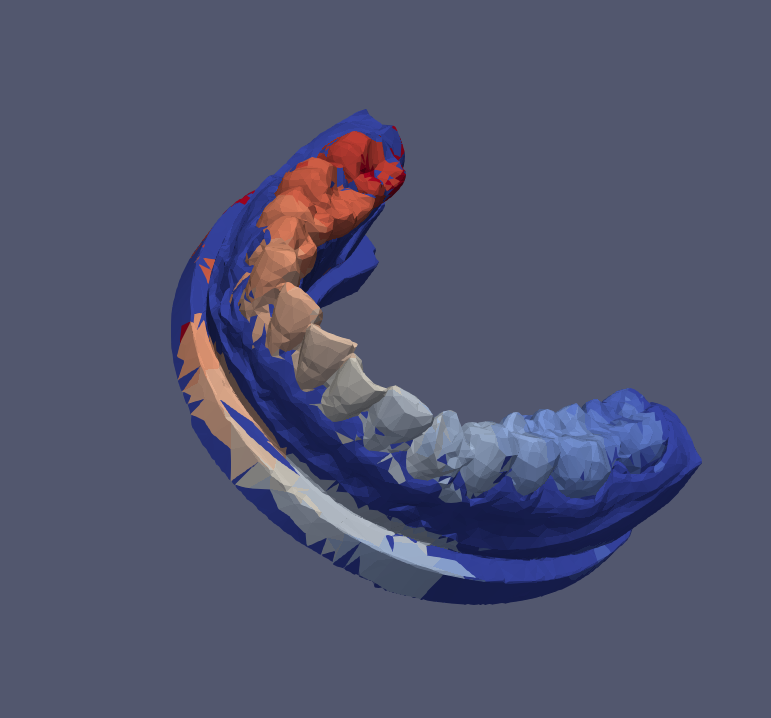
- 结果优化-图切
- 文件:
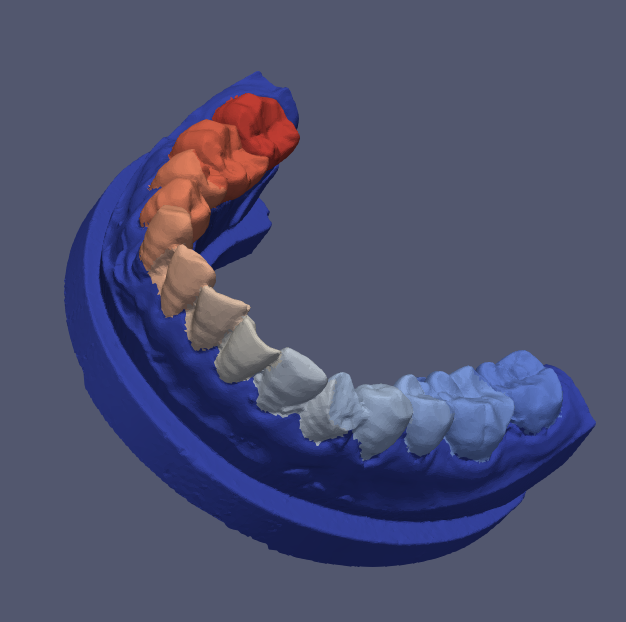
step6_predict_with_post_processing_pygco.py- python包pygco实现
- 得到降采样后的模型
Example_d_predicted_refined.vtp(简化模型),升采样后的模型Example_predicted_refined.vtp(通过KNN进行还原的网格)
- 文件: