自动摘要: 简介: 1.隶属于openmmlab旗下,专注于pytorch二维分割; 2.适用于Linux,Windows和macOS。它需要Python3.6+,CUDA9.2+和PyTorch1. ……..
简介:
- 隶属于openmmlab旗下,专注于pytorch二维分割;
- 适用于Linux,Windows和macOS。它需要Python 3.6+,CUDA 9.2+和PyTorch 1.3+;
- 官方教程地址:https://mmsegmentation.readthedocs.io/en/latest/get_started.html
安装:
安装核心**mmcv(默认认为已经安装好cuda-pytorch)**;
1
2pip install -U openmim
mim install mmcv-full从源码安装框架
- 不要想着用官方pip安装,不然修改文件需要到python包目录下,一些官方示例不好运行,因为用pip安装不好找到对应测试样本。
1
2git clone https://github.com/open-mmlab/mmsegmentation.git
cd mmsegmentation
- 不要想着用官方pip安装,不然修改文件需要到python包目录下,一些官方示例不好运行,因为用pip安装不好找到对应测试样本。
测试
需要下载配置和检查点文件。
1
mim download mmsegmentation --config pspnet_r50-d8_512x1024_40k_cityscapes --dest .
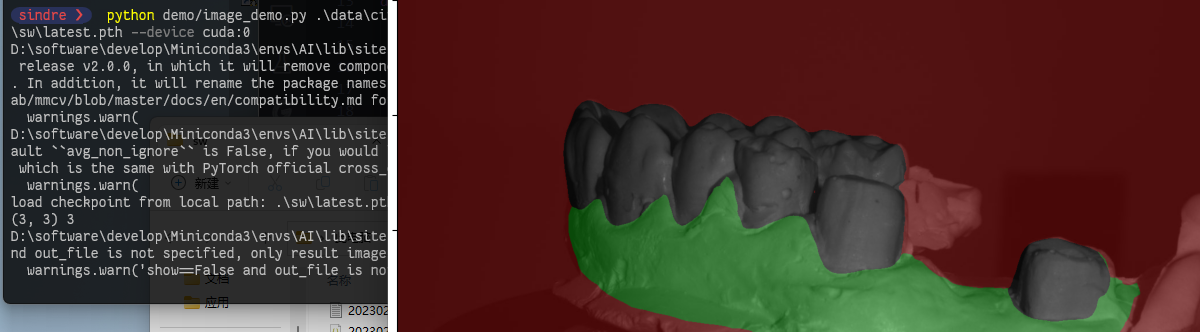
推理演示.
1 | python demo/image_demo.py demo/demo.png configs/pspnet/pspnet_r50-d8_512x1024_40k_cityscapes.py pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth --device cuda:0 --out-file result.jpg |
- 将在当前文件夹中看到一个新图像,其中分割蒙版覆盖在所有对象上。result.jpg
训练自己的数据:
- 官方https://mmsegmentation.readthedocs.io/en/latest/dataset_prepare.html上提供了各种类型开源数据集加载方式,原则上只要做成类似的就可以快速跑起来。
- 因没有过多深入这个框架,也懒得学,因为只给我2个小时时间, 所以采用直接修改源码。
- 数据可以用labelme(https://github.com/wkentaro/labelme)制作和生成。
- 准备数据:创建data文件夹,data内我们放入x(输入源),y(输出源)
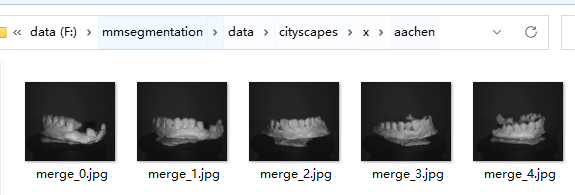
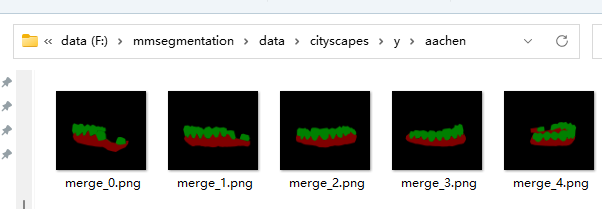
注意:输入为灰度图,标签为8bit的标签图。
- 修改源码:我们尝试修改官方提供的cityscapes的数据加载器,让其适应我们的数据,从而达到cityscapes类就是我们需要的类,这样官方所有模型都可以跑;
- 思路:pytorch数据加载器一定是通过自身dataset加载,所以找到对应代码,把对应标签改成我们这样的3类(牙,牙龈,背景)即可,然后加载数据让其只认尾缀jpg,png加载,不用特定适应cityscapes名称;
- 本例默认使用HRNET,配置索引在:\configs\hrnet\fcn_hr18_512x1024_160k_cityscapes.py。
**”datasets\cityscapes.py” **是mmseg框架的数据加载器;将其改为如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
class CityscapesDataset(CustomDataset):
"""Cityscapes dataset.
The ``img_suffix`` is fixed to '_leftImg8bit.png' and ``seg_map_suffix`` is
fixed to '_gtFine_labelTrainIds.png' for Cityscapes dataset.
"""
CLASSES = ('teeth', 'gum', 'background') # 类别
PALETTE = [[128, 0, 0], [0, 128, 0], [0, 0, 0]] # 标签对应类别颜色
def __init__(self,
img_suffix='.jpg', # 输入源只认jpg尾缀
seg_map_suffix='.png',# 输入源只认png尾缀
**kwargs):
super(CityscapesDataset, self).__init__(
img_suffix=img_suffix, seg_map_suffix=seg_map_suffix, **kwargs)“configs_base_\datasets\cityscapes.py” 是mmseg框架的数据配置文件,将其修改如下,我这里图方便。如果还需改图片大小等,可以在里面自定义。
“lib/models/bn_helper.py”,
1 | data = dict( |
- 开始训练
1
python .\tools\train.py .\configs\hrnet\fcn_hr48_512x1024_160k_cityscapes.py --work-dir ./sw/ --deterministic --no-validate
推理:
- 需要修改mmseg\core\evaluation\class_names.py ,否则推理会默认按照开源数据的类别去推理,改成如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23def cityscapes_classes():
"""Cityscapes class names for external use."""
# return [
# 'road', 'sidewalk', 'building', 'wall', 'fence', 'pole',
# 'traffic light', 'traffic sign', 'vegetation', 'terrain', 'sky',
# 'person', 'rider', 'car', 'truck', 'bus', 'train', 'motorcycle',
# 'bicycle'
# ]
return [
'teeth', 'gum', 'background'
]
# 137行也要改成下面这样
def cityscapes_palette():
"""Cityscapes palette for external use."""
# return [[128, 64, 128], [244, 35, 232], [70, 70, 70], [102, 102, 156],
# [190, 153, 153], [153, 153, 153], [250, 170, 30], [220, 220, 0],
# [107, 142, 35], [152, 251, 152], [70, 130, 180], [220, 20, 60],
# [255, 0, 0], [0, 0, 142], [0, 0, 70], [0, 60, 100], [0, 80, 100],
# [0, 0, 230], [119, 11, 32]]
return [[128, 0, 0], [0, 128, 0], [0, 0, 0]]1
python demo/image_demo.py .\data\cityscapes\x\aachen\merge_0.jpg .\sw\fcn_hr48_512x1024_160k_cityscapes.py .\sw\latest.pth --device cuda:0