自动摘要: 变更记录 |版本号|作者|修订内容|发布日期| ||||| |1.0.0|[@邵巧钰(shaoqi ……..
变更记录
| 版本号 | 作者 | 修订内容 | 发布日期 |
|---|---|---|---|
| 1.0.0 | @邵巧钰(shaoqiaoyu) | 创建初始内容 | 2022-06-10 |
| 1.1.0 | @邵巧钰(shaoqiaoyu) | 修改数据目录,增加数据数量 | 2022-06-15 |
| 1.2.0 | @邵巧钰(shaoqiaoyu) | 增加数据链接,修改文档排版、数据样例 | 2022-06-16 |
| 1.2.1 | @邵巧钰(shaoqiaoyu) | 修改数据样例描述 | 2022-06-16 |
| 1.3.1 | @邵巧钰(shaoqiaoyu) | 修改数据数量,数据目录,命名规范,数据链接,数据样例。文档名称 | 2022-06-17 |
| 1.4.1 | @邵巧钰(shaoqiaoyu) | 完善数据制作流程(增加图片),增加数据术语 | 2022-06-20 |
| 1.5.1 | @邵巧钰(shaoqiaoyu) | 修改数据数量 | 2022-06-22 |
| 1.5.2 | @邵巧钰(shaoqiaoyu) | 修改错误内容 | 2022-06-23 |
| 1.5.3 | @sindre(sindre) | 添加部分说明 | 2022-07-09 |
| 1.5.4 | @邵巧钰(shaoqiaoyu) | 添加数据 | 2022-08-05 |
| 1.5.5 | @邵巧钰(shaoqiaoyu) | 添加数据 | 2022-09-27 |
| 1.5.6 | @邵巧钰(shaoqiaoyu) | 添加数据20份 | 2022-09-29 |
| 1.5.7 | @邵巧钰(shaoqiaoyu) | 添加数据并修改数据数量 | 2022-10-14 |
| 1.6.7 | @邵巧钰(shaoqiaoyu) | 修改数据内容,增加数据问题 | 2022-10-22 |
| 1.7.7 | @邵巧钰(shaoqiaoyu) | 添加数据及其描述 | 2023-02-20 |

1. 数据介绍
1.1 数据背景
- 数据来源于CAD
- 通过我司正畸软件(唐怀宽)版进行手工标注
1.2 应用场景
| 场景 | 场景应用 |
|---|---|
| 正畸 | 自动分牙 |
| 正畸 | 牙龈生成 |
| CAD | 全冠生成 |
| CAD | 牙齿识别 |
2. 数据概述
2.1 数据定位
- 主要用于牙齿分割
2.2 数据数量
分牙数据-已处理 1332份(缺少600717号下颌数据)特别数据-24份总计:1356份数据
2.3 命名规范
三个文件夹里的文件名一一对应
2.4 数据链接
http://192.168.1.55:9003/f/89412
2.5 数据目录
1 | C:. |
2.6 数据样例
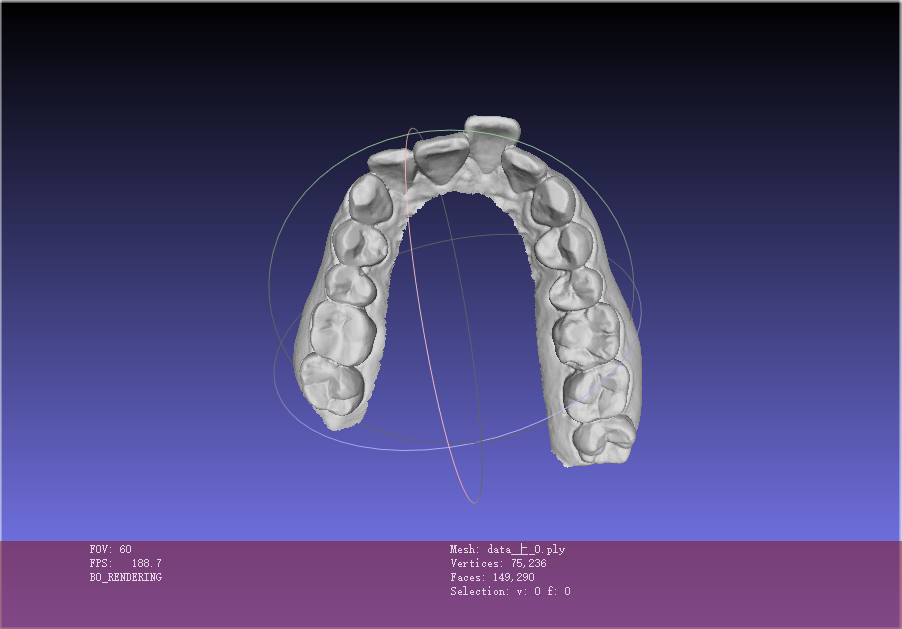
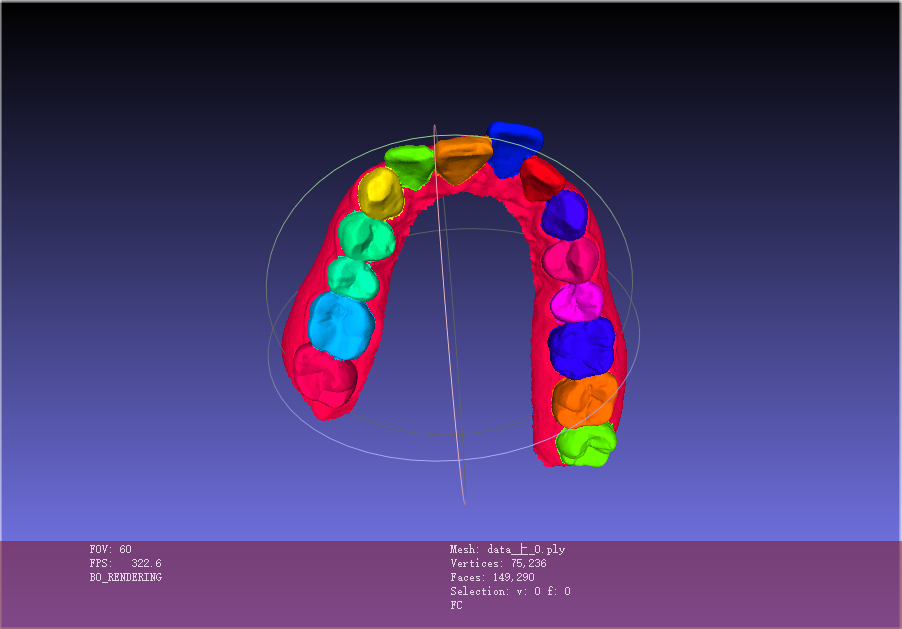
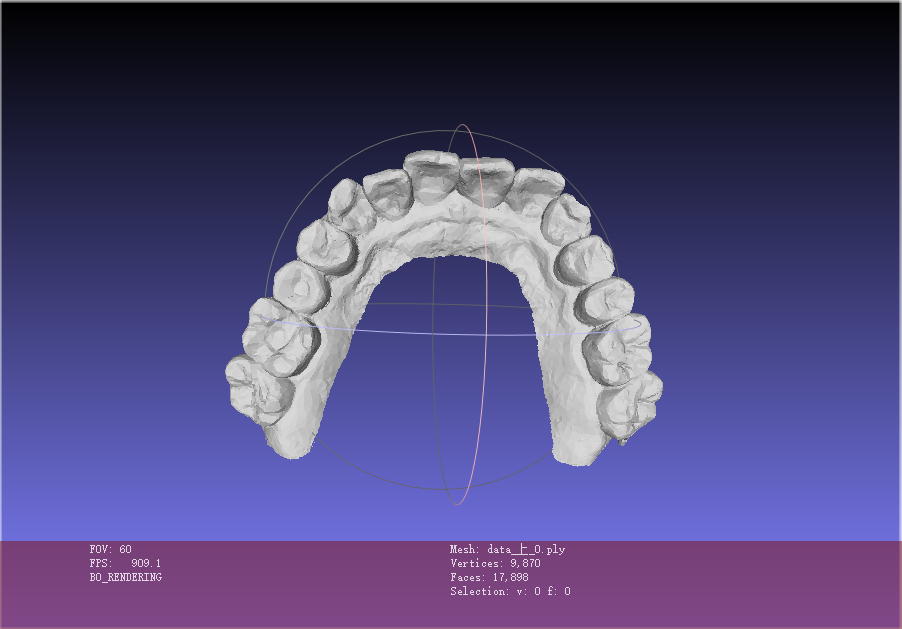
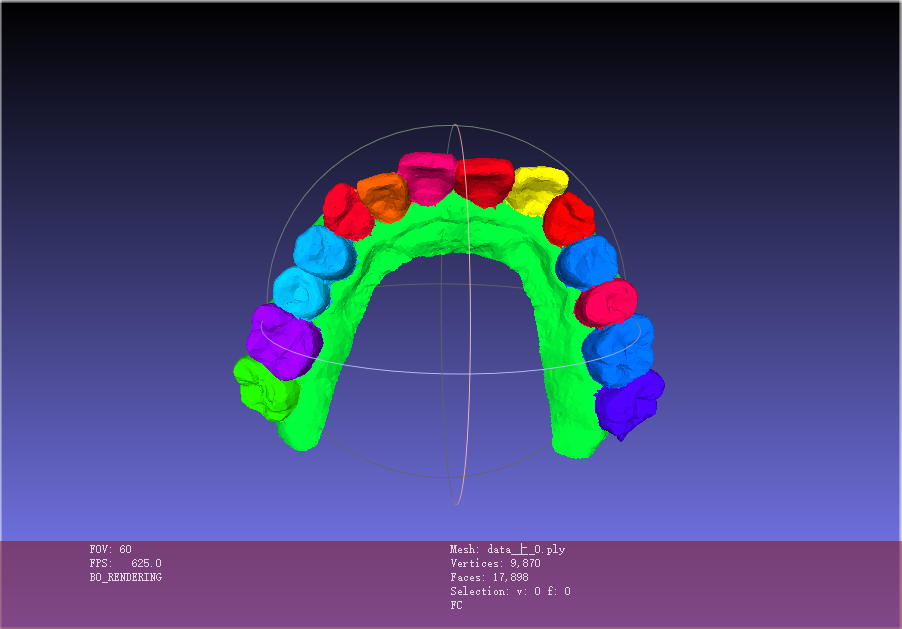
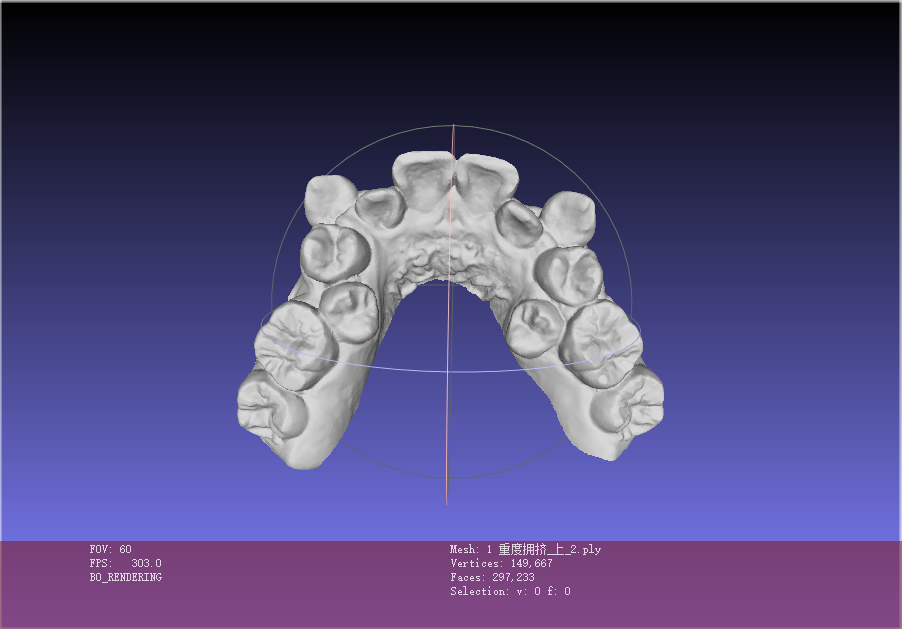
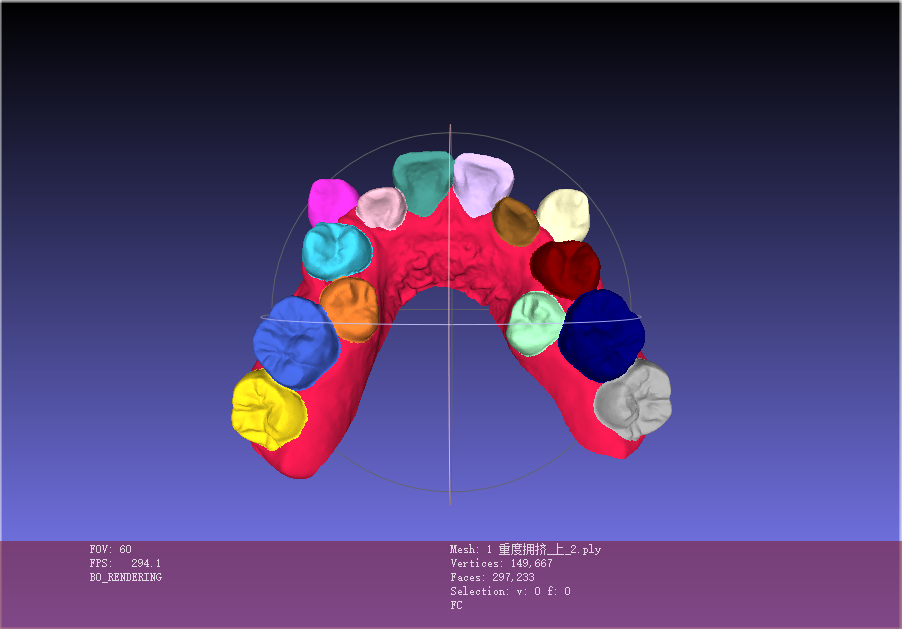
2.7 数据制作流程
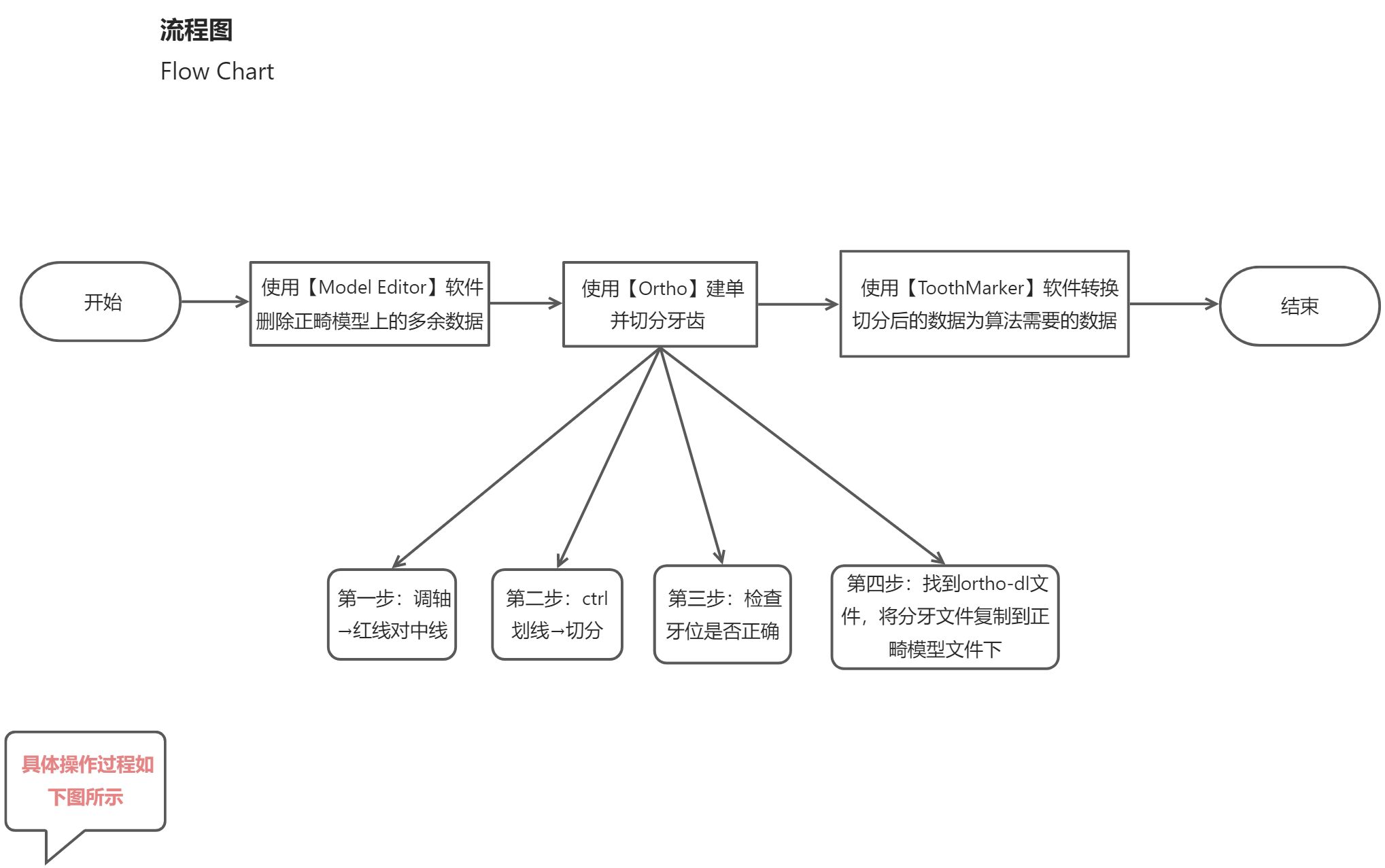
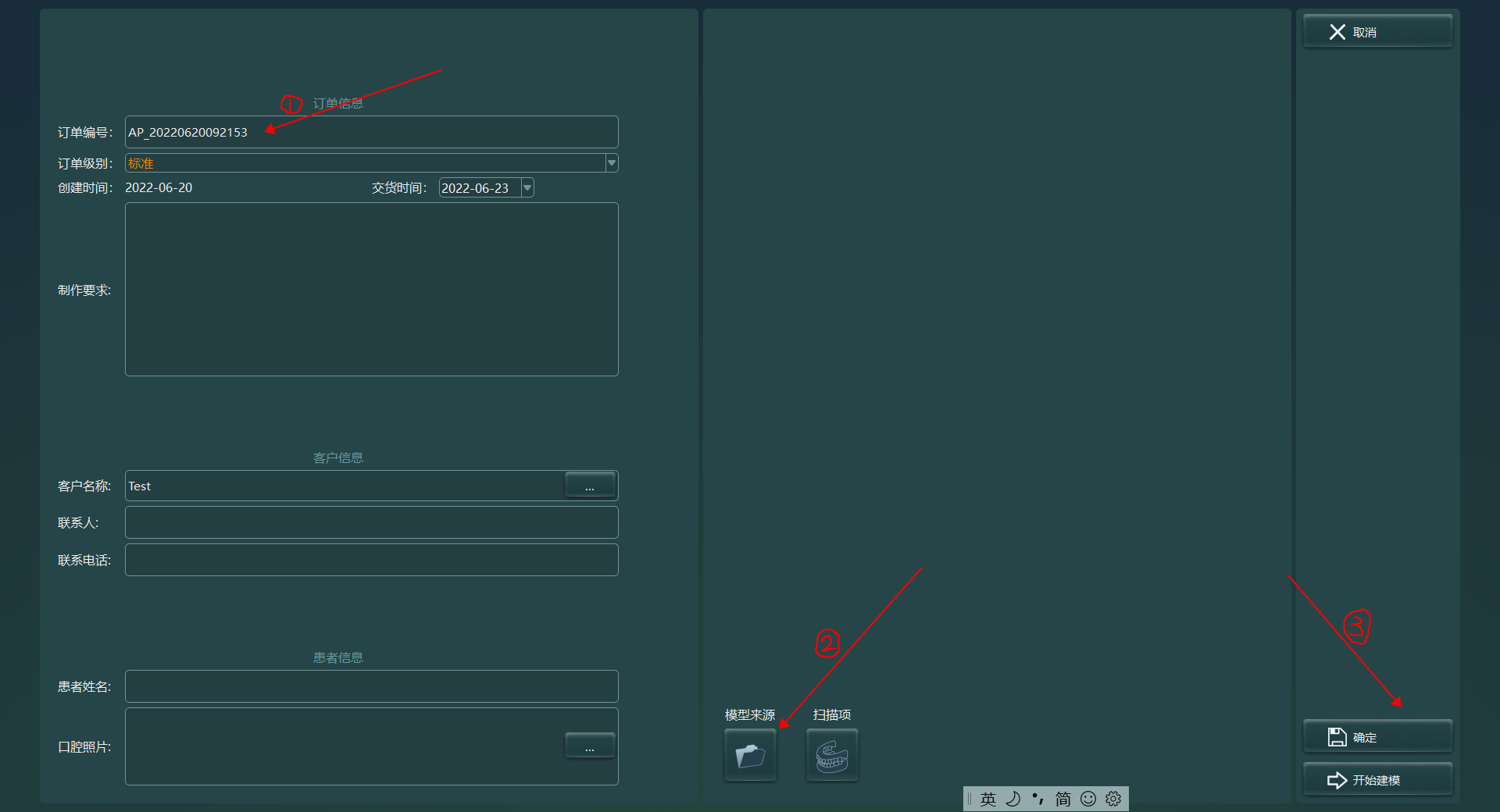
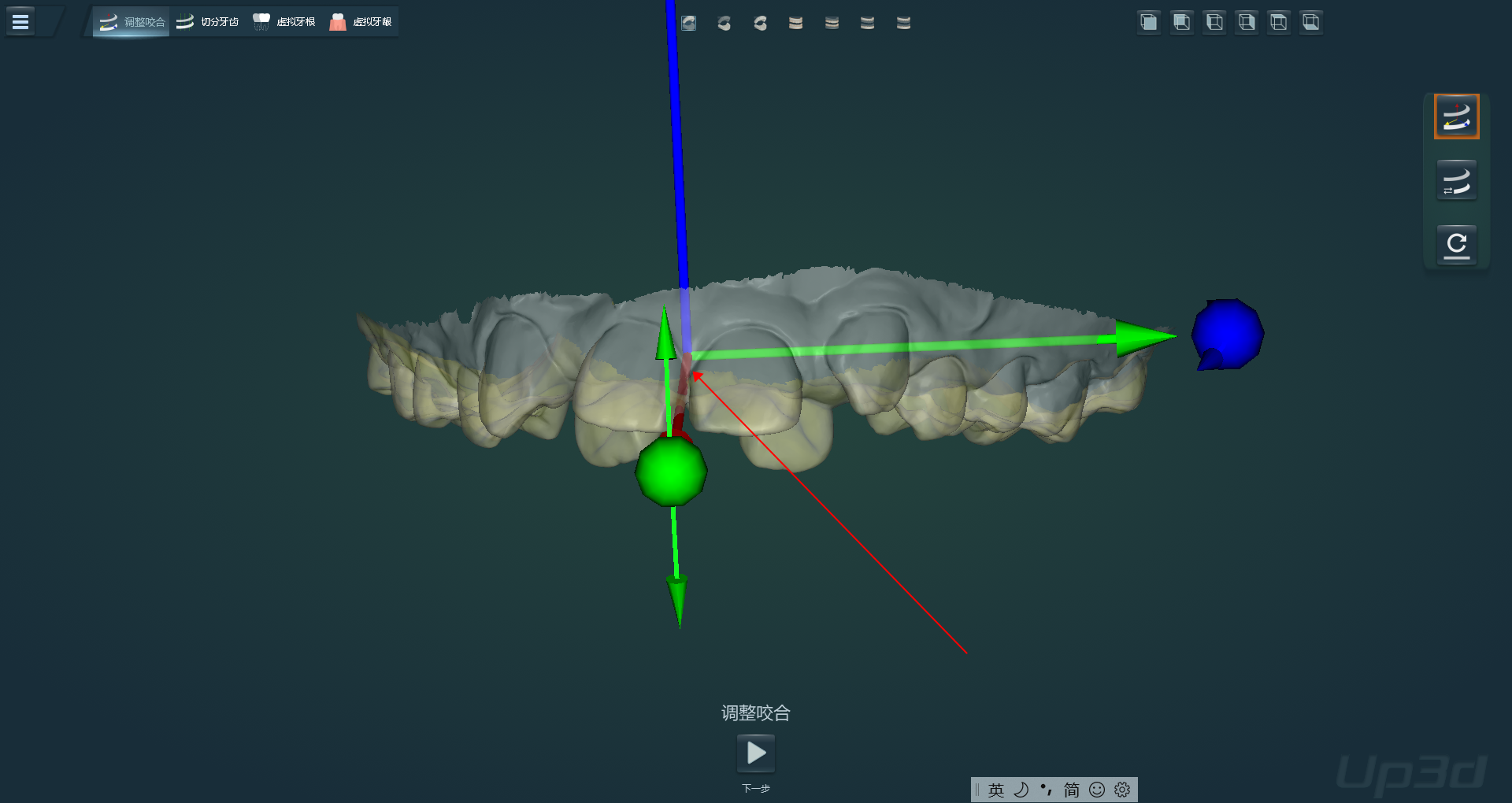
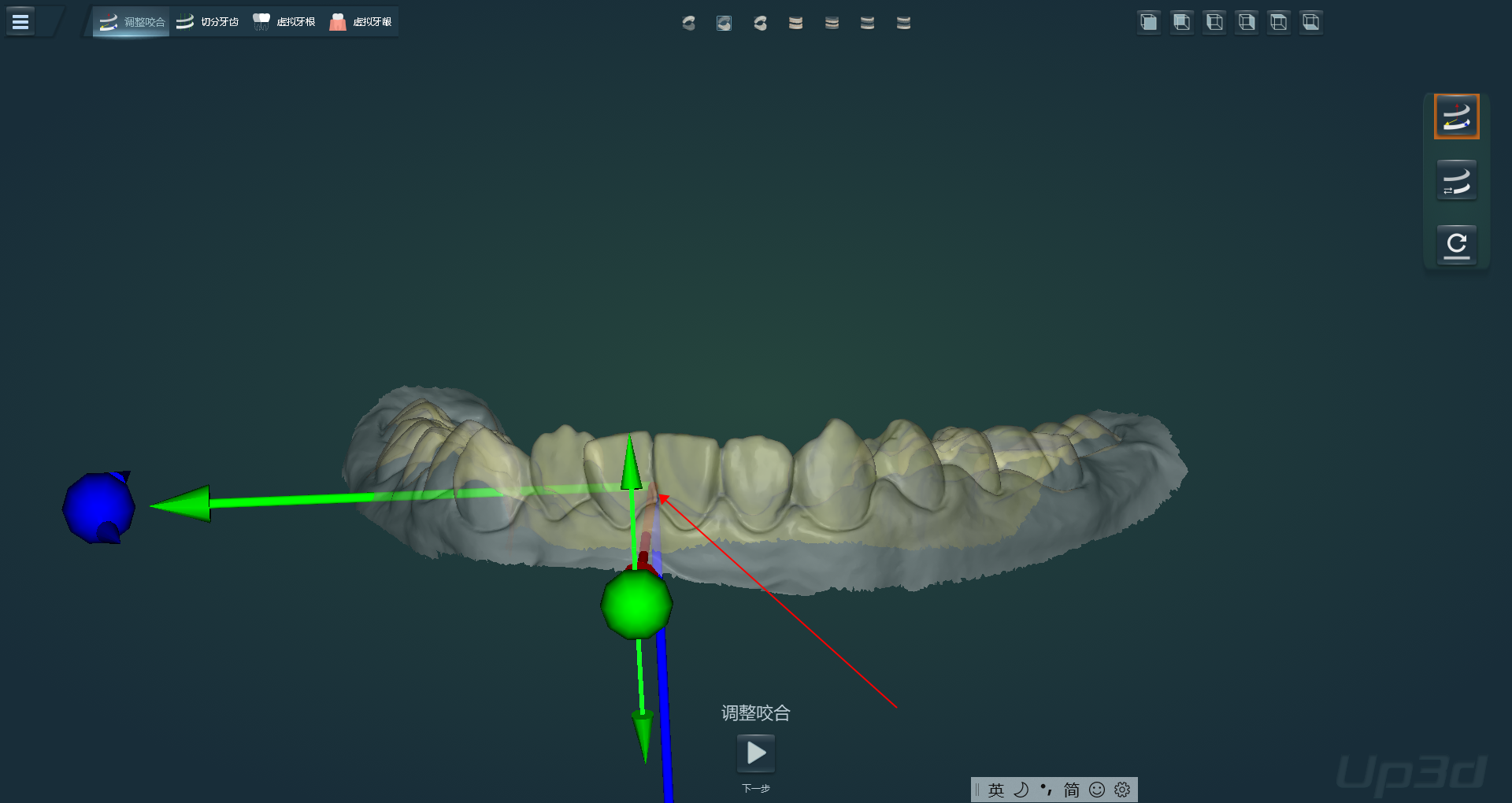
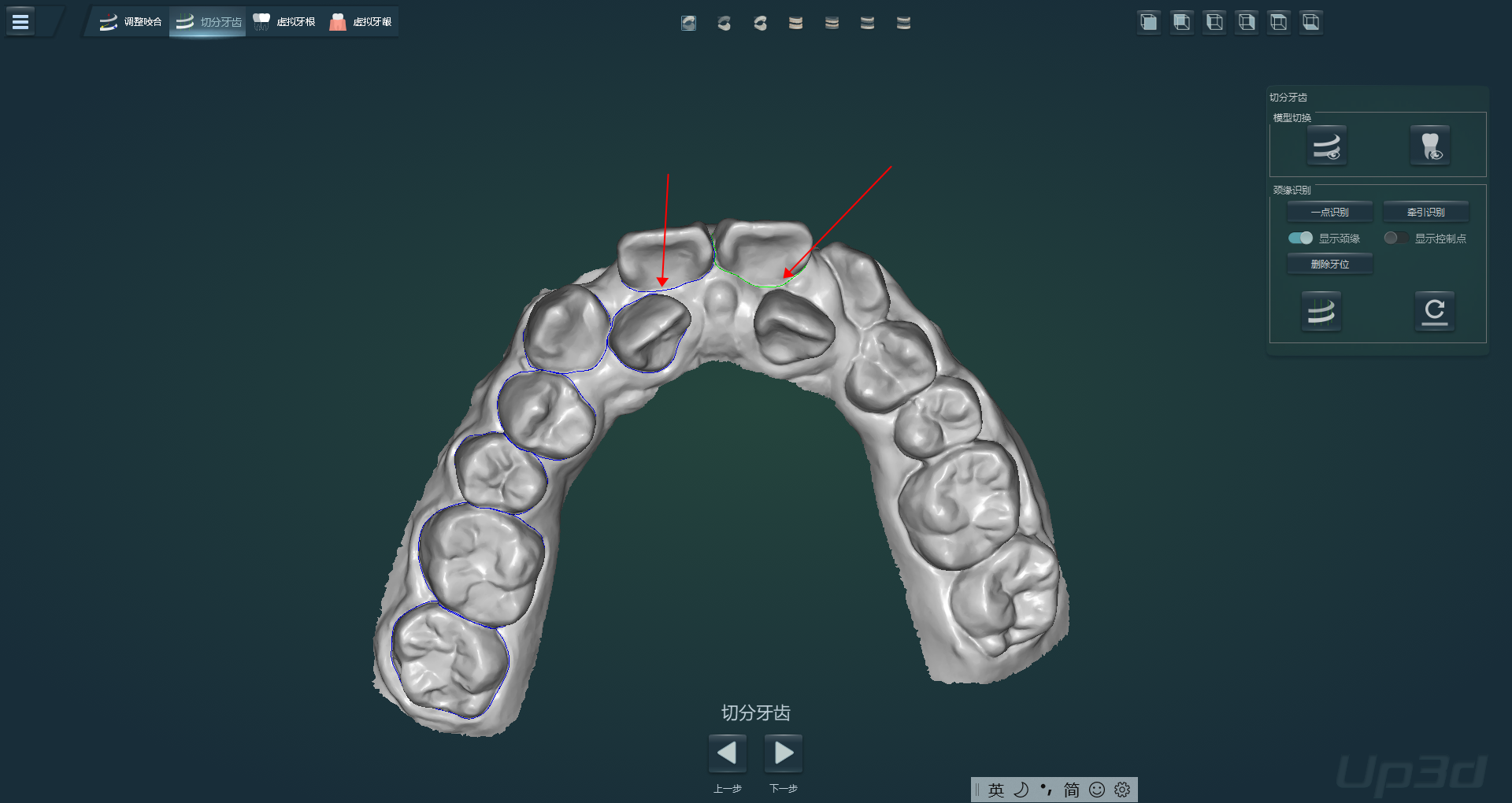
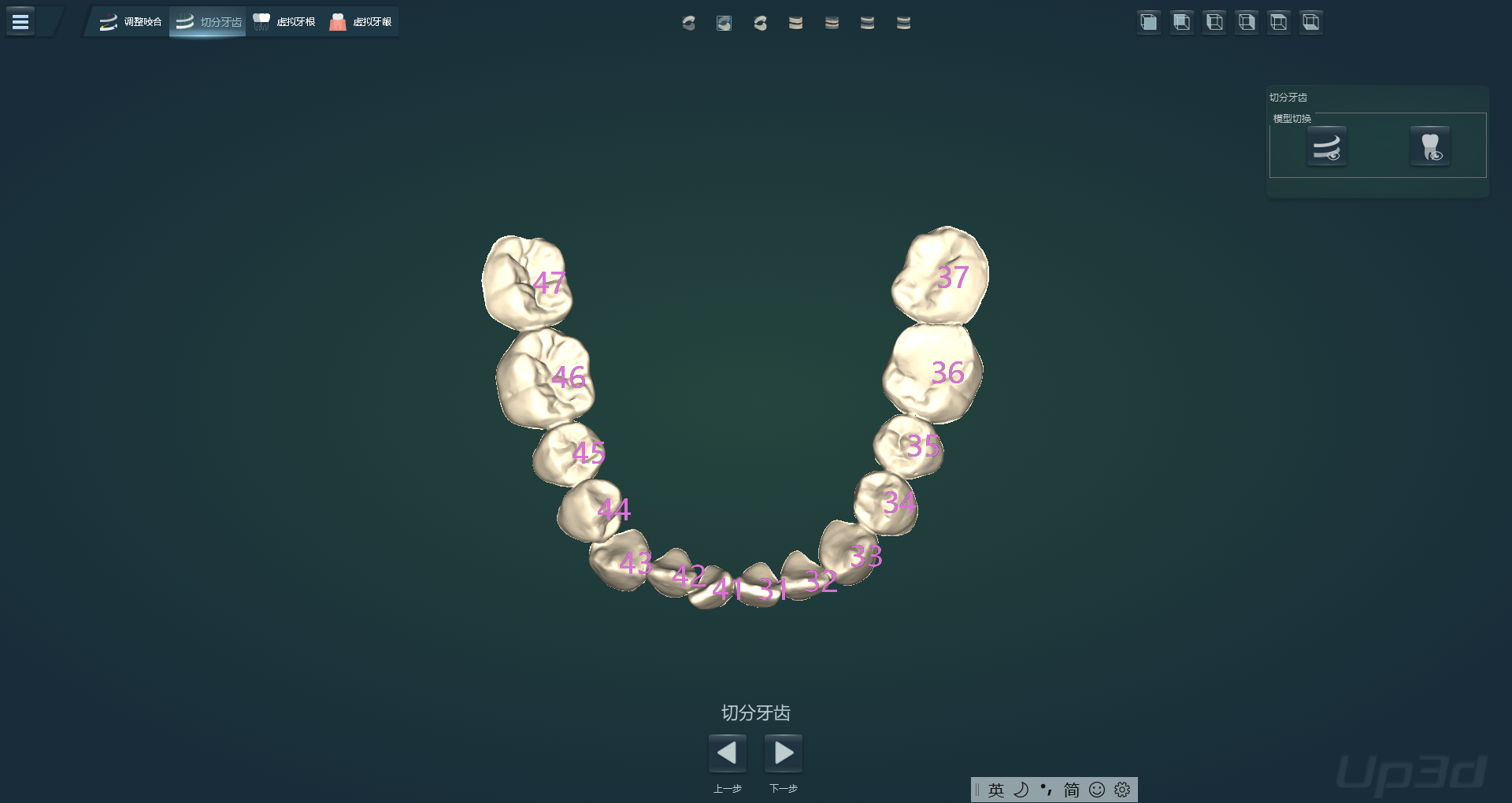
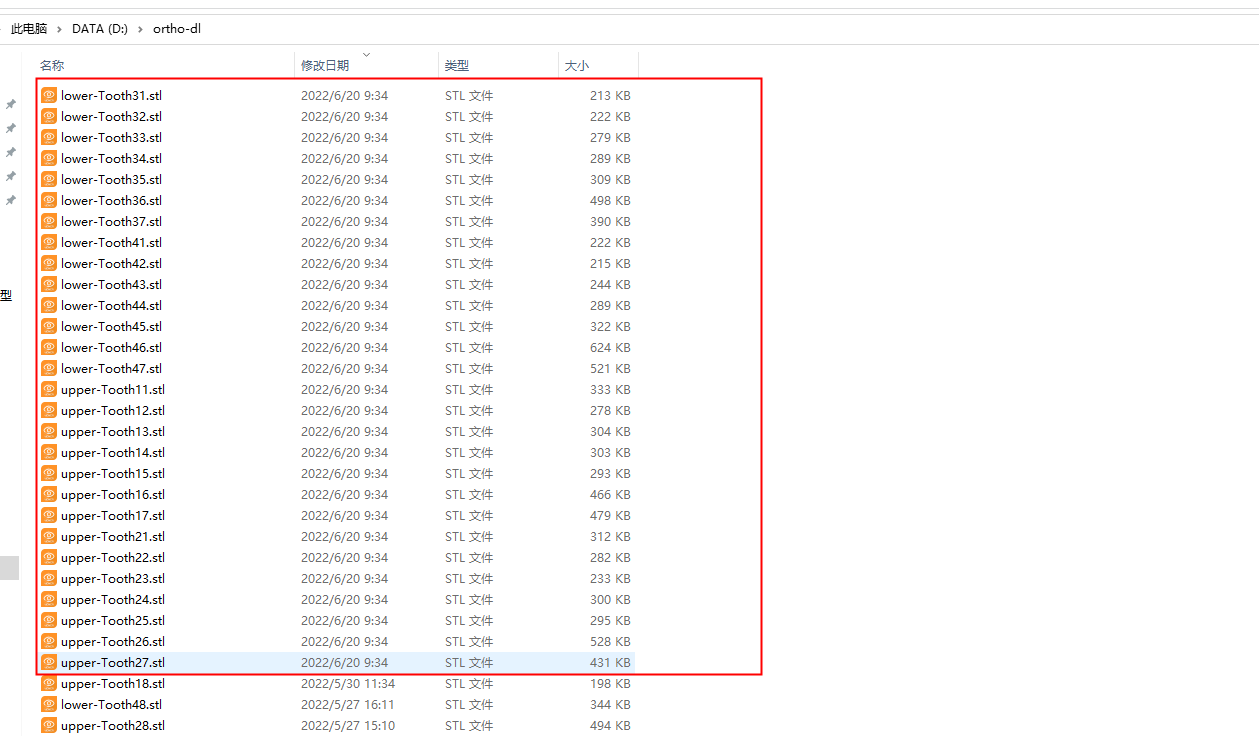
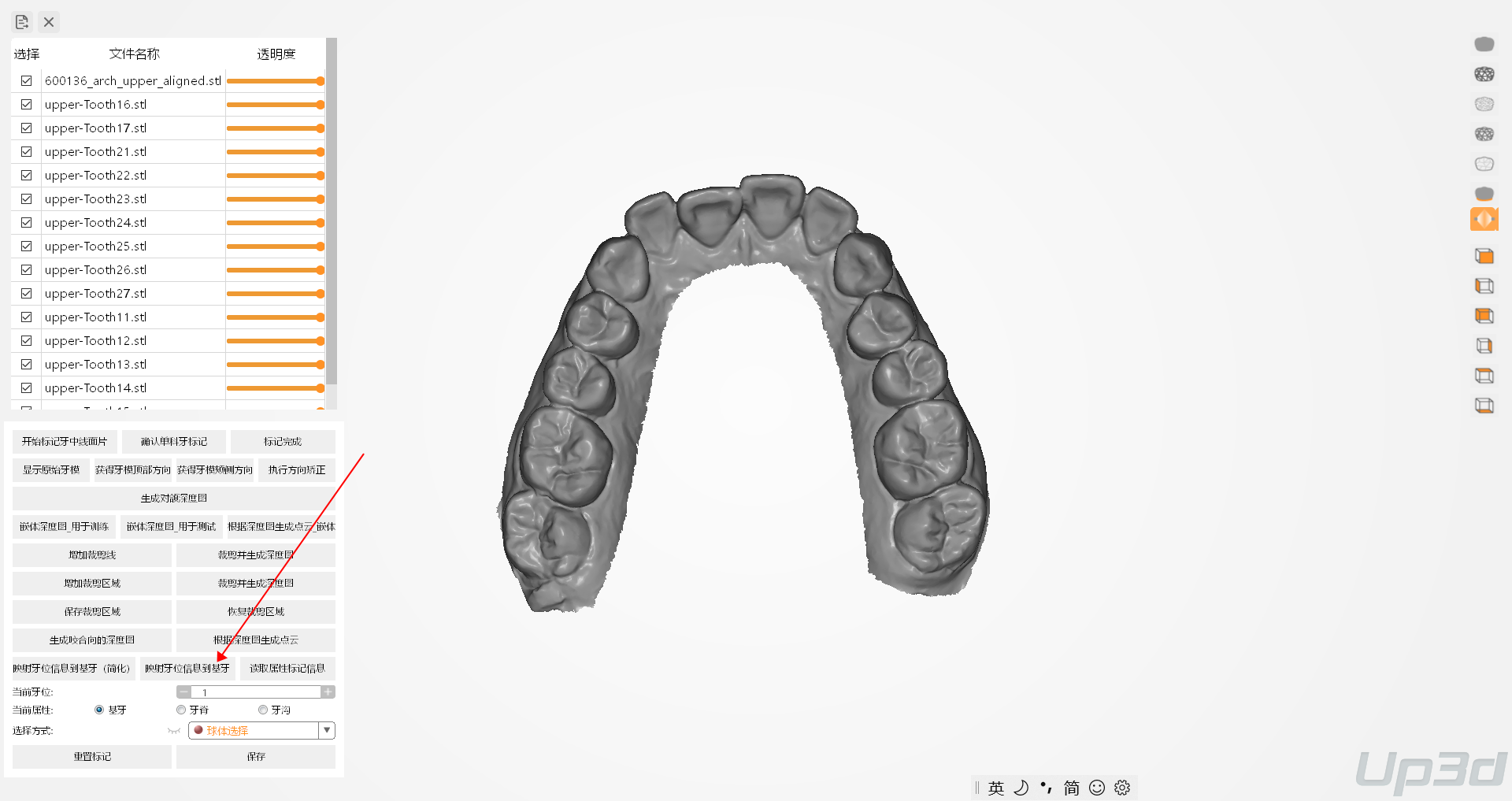
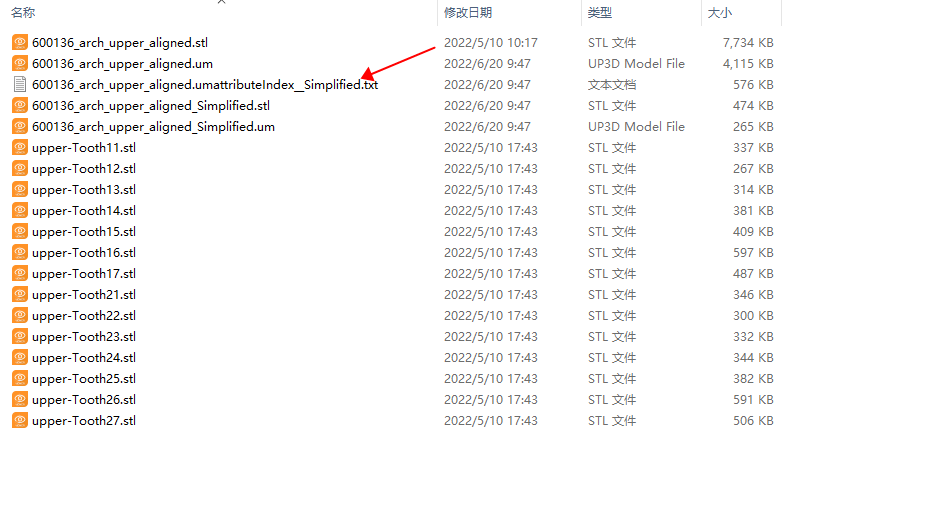
2.8 数据术语
| 术语 | 定义 |
|---|---|
| 正畸 | 矫正牙齿、解除错牙和畸形,美观牙齿。 |
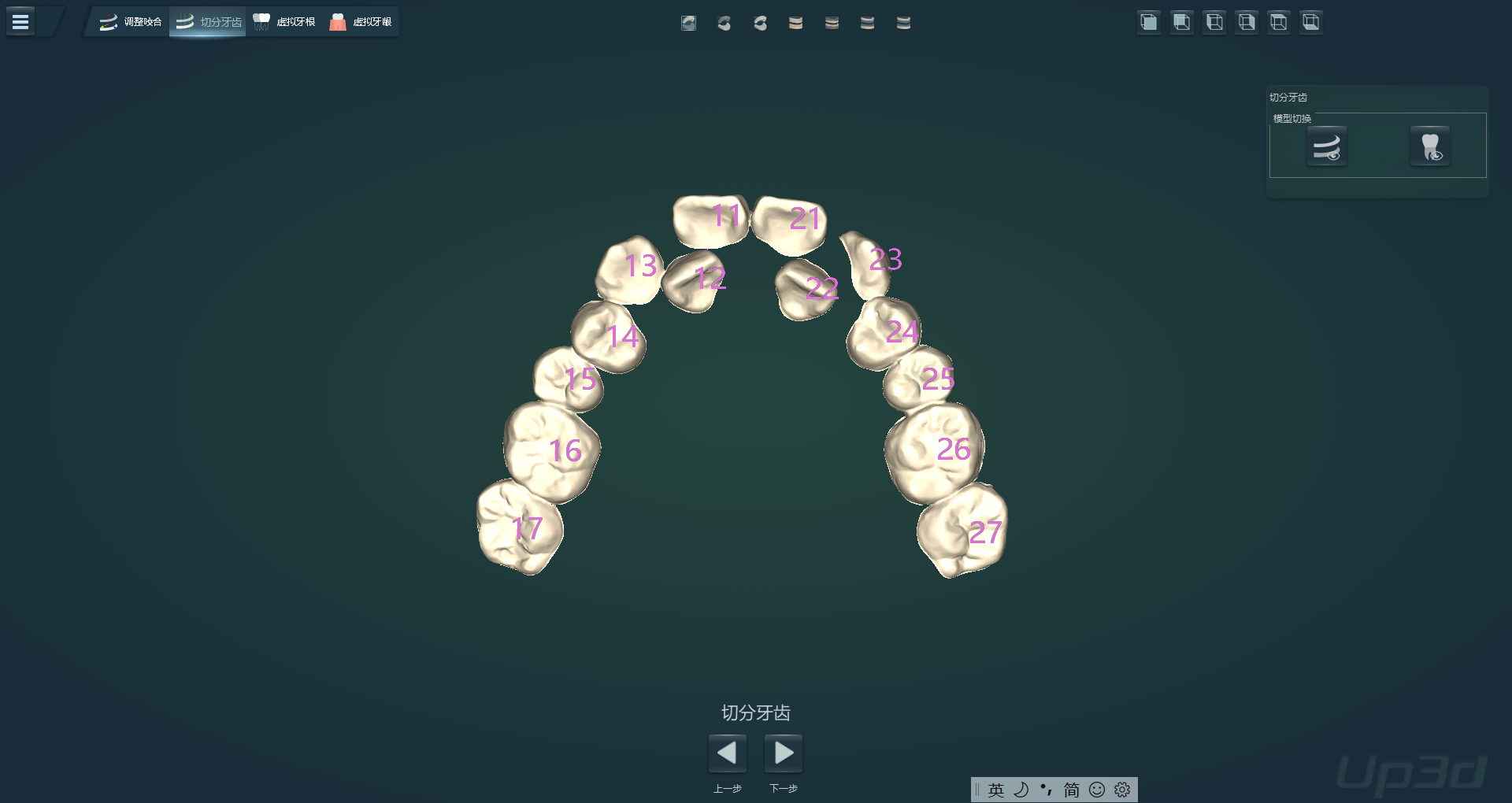
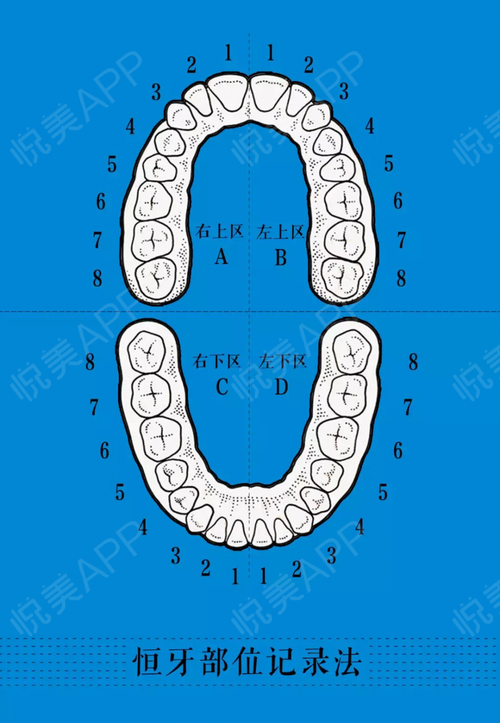
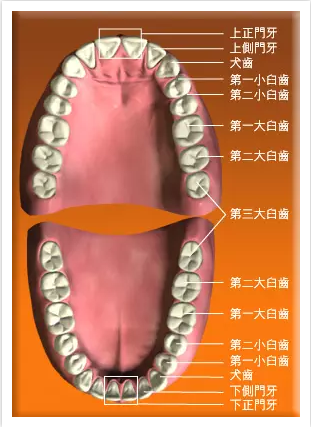
| 牙位号(图) | 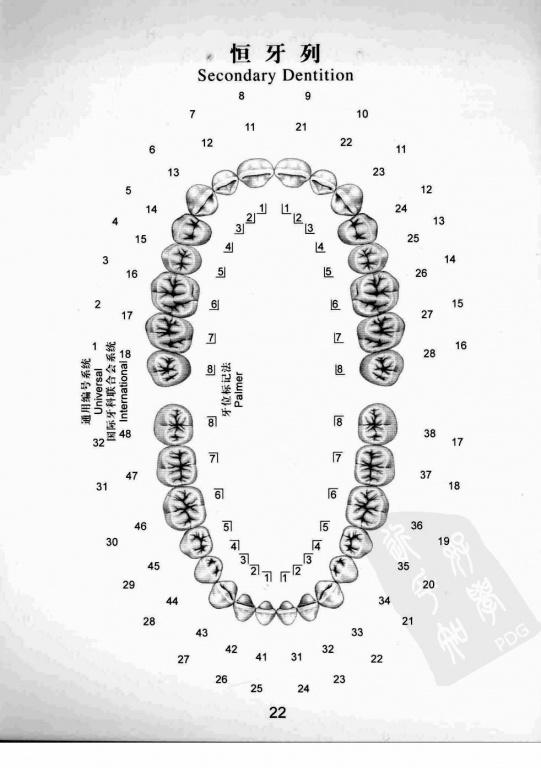 |
 |
|
 |
|
3. 现阶段问题
数据问题:
@sindre(sindre)600717号下颌数据存在问题(上述数据中已删除该份下颌数据)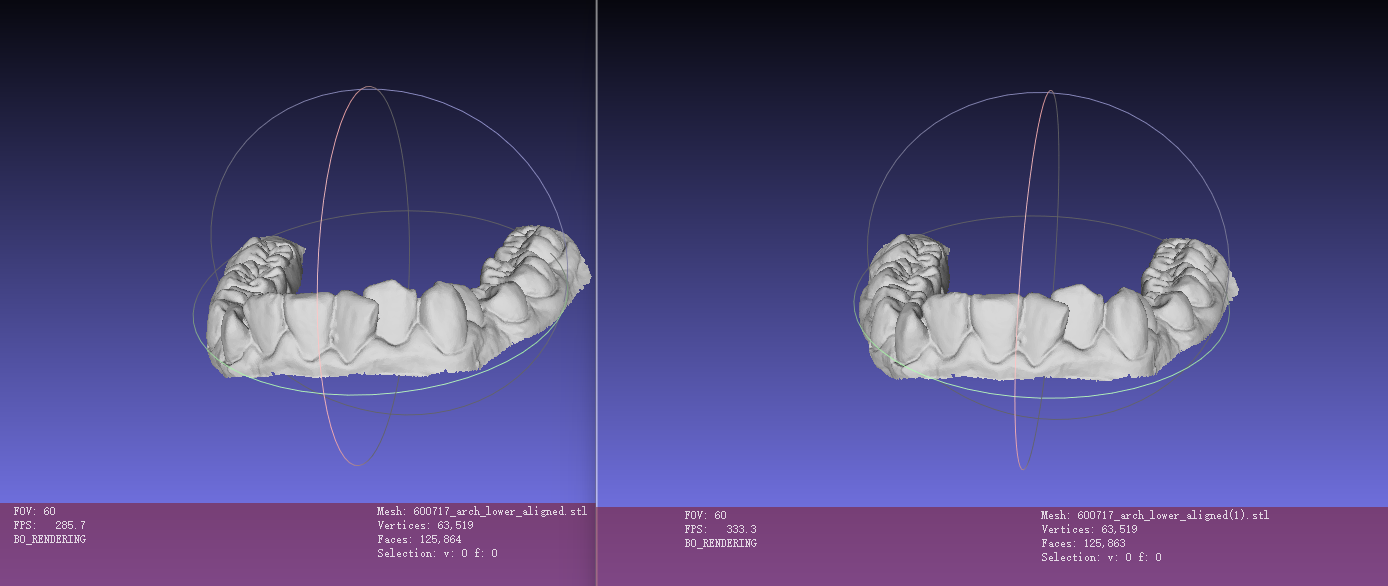
错误:分割标签与stl模型不匹配 (125864——>125863)现象:stl显示有125864面片,标签只有125863个,um显示有125863面片 (如图)可能原因: um转换成stl 多了个face解决方法: 用modeleditor重新将um导出stl后,面片数正常
修复后数据出现大量噪音,故删除600717号下颌数据
特别数据:
包含以下数据
- 测试组反馈效果不佳的数据:4份(上下颌)
- 筛选的牙龈多的数据:4份(上下颌)
- 正畸用于展会展示的数据(重度拥挤、少量间隙、牙列不齐、轻微覆盖):4份(上下颌)
4. 未来计划
- 提高分牙数据格式的统一性
数据内容规范:
数据格式统一为LMDB,主要有以下原因:
- 有些服务器硬盘为机械硬盘,LMDB可映射内存,较少io影响。
- 数据小文件过多,存在传输过慢和丢失现象,而LMDB只有一个文件。
- 不同文件格式过多,如5颗牙分牙数据,16颗分牙数据,每次数据处理需要做大量判断,重复检查。
数据上下颌统一为如下格式,因为上下颌存在咬合关系不一定对,所以保留上下咬合关系没有用,如果用于排牙训练,只需把排好牙的数据打乱即可,而不用分牙数据替代。
LMDB规范,一个mdb文件含有两个数据库,一个meta数据库,一个为data数据库,其中data数据库为(str,np.array)键值对类型,其中值通过msgpack.packb压缩成二进制。
- meta数据库:
- nb_samples:数据集大小(int);
- description: 数据集描述(str);
- data数据库:
键值 描述 类型 形状 name 数据原有名字 data_source 数据来源 mesh_vertices 这是三角网格中的顶点坐标信息,用于定义网格的形状和位置。 mesh_faces 这是三角网格中的面片索引信息,用于连接顶点并定义网格的拓扑结构。网格面片索引 vertex_labels 这是对牙弓牙齿每个顶点进行的标记或分类,可能用于区分不同类型的牙齿或其他目的。 face_labels 这是对牙弓的每个面片进行的标记或分类,可能用于区分不同区域、组织或其他目的。 tooth_len 这是牙弓中包含的牙齿数量,可以用于确定牙弓的大小和形状。 jaw 这是指示牙弓所属的上下颌部位的属性,通过”upper”或”lower”来表示。 unique_label 这是指牙弓中所有牙齿的唯一编号或标识符,确保每个牙齿都有一个独特的标记。 vertex_normals 这是每个顶点的法线方向信息,用于计算光照和渲染效果。 faces_normals 这是每个面片的法线方向信息,用于计算光照和渲染效果。 vertex_mean_curvature 这是基于meshlab计算得出的每个顶点的平均曲率值,可用于分析网格形状的特征和曲率变化。
- meta数据库:
tools.pyDatasetToLmdb.py

