自动摘要: 前言 入职两个月的时间里,我主要负责全冠生成模型和模扫分割模型的训练和部署工作。 个人理解 本人对部署的理解就是,在理解算法推理流程的基础上(至少要看懂python代码),用 ……..
前言
入职两个月的时间里,我主要负责全冠生成模型和模扫分割模型的训练和部署工作。
个人理解
本人对部署的理解就是,在理解算法推理流程的基础上(至少要看懂python代码),用c++复现一遍,保证结果正确或差别很小,然后使其高性能。本人习惯性将部署分为预处理,推理,后处理三个流程。在参加工作之前使用过一些常用的部署框架,但掌握的并不熟练,做过的项目也只局限于图像方面,所以在做全冠生成部署(三维)确实感到很大压力,但是最后还是做成了,尽管还有些不足(预后处理比不过numpy),但是扩宽了我的视野和领域。
工作过程
1.全冠生成(已完结)
(1)结论:
CPU: 11代i5GPU: GTX1650模型:shapenet.onnx (7.31mb)原本:cpu 总耗时约:120s优化后:onnxruntime(tensorrt_fp32后端)总耗时约10s,推理5s,预后处理5s.
(2)过程
1.替换三线性插值算子,导出onnx,重写python推理脚本(numpy)。
基础算子重构pytorch的grad_sample(三线性插值),已由组长杨新给出,但后续我导出onnx时发现结果对不上,原因在于版本,高版本的 F.grid_sample()的align_corners=False,所以需要显式的指定 F.grid_sample(net, p_ext, align_corners=True)
2.利用xtensor,open3d,onnxruntime库,重写c++推理脚本
这里说明onnxruntime的版本是onnxruntime-win-x64-tensorrt-1.13.1cuda cudnn tensorrt 版本分别为 11.4,8.4,8.4xtensor,open3d官网最新版即可
3.利用xsimd,openmp,tensorRT对算法进行优化,并将算法封装成库。
xsimd安装使用可在xtensor官方找到。openmp百度。
(3)遗留问题
1.网格转体素未对应,部署体素化采用open3d,但是算法工程师那边用的trimesh,导致结果不对应。2.体素转网格不支持,open3d不支持4个点的网格,还有一个拉普拉斯平滑操作没有做,目前只生成了点和面片。我重构的基于open3d做体素化的numpy推理脚本与c++结果完全一致(后续可以对照着改)。python位置:E:\learning_open3d\python\teeth_generatec++位置:E:\learning_open3d\c++\teeth_generatenpython_generate_deploy.py
(4)心得感悟
学到很多新技术,一条路走通了,再来就很容易。
2.模扫分割(未完结)
(1)结论:
CPU: 11代i5GPU: GTX1650模型:fcn_hr18s_512x1024_40k_cityscapes.onnx (15.0mb)原本:cpu 总耗时约:0.8s/张优化后:onnxruntime(tensorrt_fp16后端)总耗时0.13s/张,推理0.11s,预后处理0.02s.onnxruntime(tensorrt_fp32后端)总耗时0.16s/张,推理0.14s,预后处理0.02s.
(2)过程:
1.训练
参考组长杨新写的mmseg使用文档,框架教程:MMSegmentation框架简单使用-30min.pdf
1.做数据:
采用了这个库 https://github.com/aleju/imgaug原本260张,增强后16000左右。增强代码data.py原始数据和全部数据以上传至AI算法组钉盘做数据过程中遇到了一个极为棘手的问题,就是opencv无法读写8bit的png彩图,在data.py里给出了解决方案。
2.训练记录
(1)模型:fcn_hr18s_512x1024_40k_cityscapes(2)硬件:cpu:11代i5gpu: GTX 1065 (3)训练:1.杨新电脑在原始配置文件的基础上只改变了输入:1400,1600(为图片的原始输入大小)最终结果。看训练情况来看,模型基本上已经不再有收敛的趋势了。因为模型在前1000世代就已经是这个loss,基本没有下降的趋势,所以选择停掉。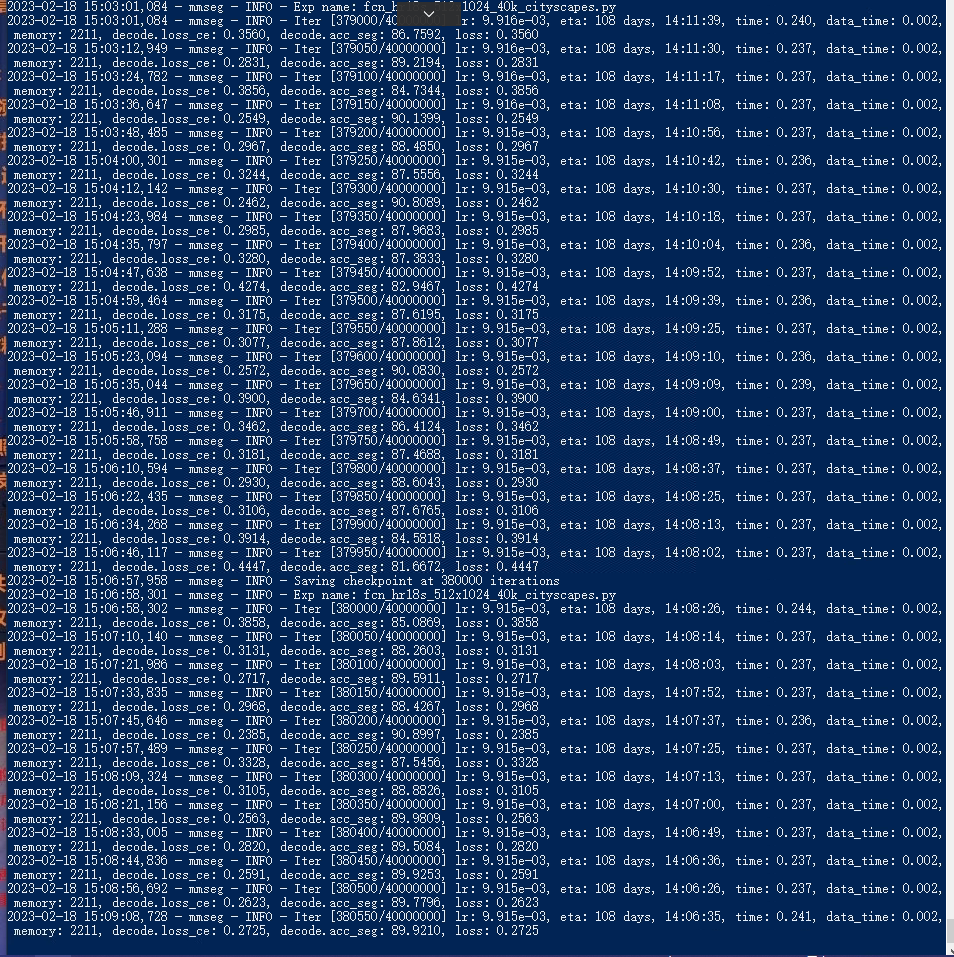
2.领用新电脑完全按照默认配置目前看loss有下降趋势,有收敛的迹象。最终:acc:98.8经过约两天时间的训练,模型并没有取得很好的效果,与经过两个小时训练的结果差不多。猜测原因是:SGD优化器的初始学习率过大1e-2,衰减幅度低,导致loss一直在震荡,无法收敛。配置文件和训练日志如下。二次:更改优化器为adam配置文件训练日志
3.叶子杨电脑在原始配置文件的基础上只改变了优化器为adam,学习率默认0.001目前loss下降平稳,预计会收敛一个好的结果。
最终效果可以接受loss:0.1,acc:0.96。因停电中断,若一直训练下去估计会有一个好效果。因停电,停掉。
2.部署:
部署相对于全冠,要简单的多,涉及到的开源库,在全冠那里基本都包含了。项目位置:E:\learning_open3d\c++\segment_deploy后续工作:部署代码比较简单,但就是速度不高,目前想到的优化的点。1.换模型(较为推荐)2.换部署框架,量化蒸馏(不推荐,可能还不如tensorrt)3.减小输入,增加一个提取预处理,然后ROI抠图,交给一个小的网络取做分割,最后再恢复到原图大小,预计性能会高得多(推荐)
3.接手
(1)导出onnx。首先我为了推理方便,将输出(1,1,1400,1600),改为(1400,1600)
然后执行
- python tools/pytorch2onnx.py ./best/fcn_hr18s_512x1024_40k_cityscapes.py –checkpoint ./best/best.pth –output-file ./best/best.onnx –shape 1400 1600
项目地址:D:\mmseg\mmsegmentation然后把生成的onnx,放在E:\learning_open3d\c++\segment_deploy\cmake-build-release-visual-studio\Release项目下就可以运行。
个人遗憾
入职的两个月里,对我个人而言真的学到了太多太多,唯一的遗憾就是时间太短了,感觉还没有学尽兴。对于我所负责的模扫分割项目而言,我暂时还没有达到预期的要求,迫于时间原因,未能实现下一步的解决方案。
团队期望
感谢AI团队的每一位成员,特别感谢我的组长杨新,每次在我各种奇怪问题的轰炸下还能不厌其烦的耐心给我讲解,跟着他学到很多新技术,希望未来还可以跟他一起工作。希望接手模扫分割项目的朋友可以尝试一下上面部署方案。

