自动摘要: 标题 投影后的GAN收敛更快 SauerA,ChittaK,MüllerJ,etal.ProjectedGANsConvergeFaster[J].Advance ……..
标题
投影后的 GAN 收敛更快
Sauer A, Chitta K, Müller J, et al. Projected GANs Converge Faster[J]. Advances in Neural Information Processing Systems, 2021, 34.
摘要
生成式对抗网络(Generative Adversarial Networks, GANs)产生的图像质量很高,但是训练难度很大。因为其需要仔细地正则化、大量的计算和代价极高的超参数扫描。我们通过将生成的真实样本投影到一个固定的预处理是预处理特征空间中,从而在这些问题上取得了重大的进展。我们是基于鉴别器不能充分利用预训练模型更深层的特征这一发现,提出了一种更加有效地跨越通道和分辨率的混合特征策略。我们的投影 GAN 改善了图像的质量、样本效率和收敛速度,还与分辨率高达100万像素的图像兼容,并在 22 个基准数据集上发展了 Frechet Inception 距离(FID)。最重要的是,投影GAN对应以前最低的 FID 值时可以加速40倍,在相同的计算资源下,将挂钟时间从5天缩短到3个小时。
关键词
GAN, FID, Projected GAN,
Sec01 介绍
GAN是由生成器和鉴别器组成。对于图像合成,生成器的任务是生成一幅 RGB 图像;鉴别器的目标是区分真假样本。仔细观察,鉴别器的任务是双重的:
- 它将真实样本和伪造样本投影到一个有意义的空间,即学习输入空间的表示;
- 它基于表示进行鉴别。
不幸的是,联合训练鉴别器和生成器是众所周知的困难任务。虽然鉴别器正则化技术有助于平衡对抗游戏[43],但是像梯度惩罚[50]这样的标准正则化方法容易受到超参数选择[33]的影响,并且可能导致性能大幅下降[5]。
在本文中,我们探讨了预训练表示在改善和稳定 GAN 的训练中的应用。在计算机视觉中[40][41][62]和自然语言处理中[24][59][61],使用预训练表示已经无所不在。虽然将预训练感知机网络[^73]与 GAN(用于图像到图像转换)相结合已经产生了令从印象深刻的结果[19][63][75][8],但是这个概念还没有在无条件的噪声到图像的合成任务中实现。事实上,我们也证实了这个想法的简单应用并不会导致很棒的结果(Sec04),因为强大的预训练特征使得鉴别器主导了联合训练过程,导致了生成器的梯度消失[^2]。在本文中,我们展示了如何克服这些困难,并且确定了利用预训练感知特征空间的全部潜能进行 GAN 训练的两个关键组成部分:特征金字塔,以实现具有多个鉴别器的多尺度反馈;随机投影,更好地利用预训练网络的更深层。

图1:投影 GAN 的收敛性。在 AFHQ-Dog 数据集上,训练期间固定隐编码的样本进化[^7]。我们发现在投影特征空间中的鉴别器特征加速了收敛性并产生了更低的FID值。这个发现在许多数据集上都保持了一致性。
我们在分辨率高达的小型和大型数据集上进行了大量的实验。在所有的数据集上,我们展示了最先进的图像合成结果,即训练时间显著减少(图1)。我们还发现投影 GAN 提高了数据的效率,并且避免了额外的正则化,使得高代价的超参数扫描也不再需要。代码、模型和补充的视频可以参考项目主页:https://sites.google.com/view/
Sec02 相关工作
我们将相关工作分为两个主要领域:GAN的预训练和鉴别器的设计。
用于 GAN 训练的预训练模型。在 GAN 中利用预训练表示的工作可以分为两大类:
- 将 GAN 的一部分转移到新的数据集中[21][52][82][88];
- 使用预训练模型来控制和改善 GAN。
因为后者不需要对抗,因此其预训练更有优势。我们的工作也属于第二类,预训练模型可以被用作一种引导机制,用于解锁因果生成因子[69],用于文本驱动的图像操作[58],将生成器的激活与反向的分类器匹配[25][71],或者在生成器的隐空间中通过梯度上升来生成图像。[^68]中的非对抗性方法在预训练模型中学习带有矩匹配的生成模型;然而,与标准的 GAN 相比,结果仍然相关甚远。一种既定的方法是对抗性损失和感知损失的混合[28]。通常,损失是加性混合的[15][19][45][67][81]。然而,只有在重建目标可用的情况下,即成对的图像到图像的转换设置[92],加性混合才是可能的。为了代替拥有重建目标的预训练网络,Sungatullina等人[75]提出在冻结了VGG特征后优化对抗损失。在图像转换任务中,他们展示这个方法改善了 CycleGAN[92]。在相似的主题中,[63]提出了不同的感知机鉴别器。他们使用一个预训练的 VGG,并且将其特征与预训练分割网络的预测连接在一起。这最后两个方法是特定于图像到图像的转换任务。我们解释了这些方法在更有挑战性的无条件设置中不能很好地工作,这个设置是从一从此随机的隐编码中合成整个图像的内容。
鉴别器的设计。GAN的许多研究都关注于新的生成器结构[5][33][34][86], 而鉴别器经常使用一个标准的卷积神经网络或者是生成器的镜像。显著的不同是[70][87],它们使用“编码器–解码器”鉴别器架构。然而,与我们的相比,他们既没有使用预训练特征,也没有随机投影。一个不同的工作领域考虑的是设置多个鉴别器,既可以应用于生成的 RGB 图像[13][18],也可以应用于低维投影[1][54]。使用多个鉴别器可以提高样本多样性、模型训练速度和模型训练的稳定性。然而,这些方法在当前最先进的系统中没有被使用,因为与增加的计算工作量相比收益递减。使用一个或者多个鉴别器提供多尺度反馈对于图像合成[30][31]和图像到图像的转换[57][81]都有帮助。虽然这些工作以不同的分辨率对 RGB 图像进行插值,但是我们的发现指出多尺度特征图的重要性,并且展示了与金字塔网络在对象检测[48]工作上成功的相似性。最后,为了防止鉴别器的过拟合,最近还提出了可微分的数据增强方法[32][79][89][^90]。我们发现,采用这些策略有助于充分挖掘预训练表示在GAN训练中的潜能。
Sec03 投影 GAN
GAN 的目标是对给定训练集的分布进行建模。
- 生成器 G 将从简单分布
(通常是正态分布)采样的隐向量
映射到相应的生成样本
- 鉴别器 D 将真实样本
与生成样本
区分开。
这个基本思想导致了下面的极小极大目标:
我们引入一组特征投影器 ,将真实的图像和生成的图像映射到鉴别器的输入空位是。投影 GAN 训练可以基于下面的公式:
其中,是一组独立的鉴别器,用于对不同的特征投影。请注意,我们在公式(4)中固定了
,仅优化
和
的参数。特征投影器
应该满足两个必要条件:必须可微,并且提供它们的输入的足够的统计特征,即它们应该保存重要的信息。此外,我们旨在找出特征投影器
能够将公式(1)中(难以优化的)目标转化为更适合基于梯度优化的目标。在指定我们的特征投影器的细节之前,投影 GAN 确实匹配投影特征空间中的分布。
3.1 一致性
公式(4)中投影 GAN 的目标不再是直接优化以匹配真实分布 。为了理解理想条件下的训练性质,我们考虑了[^54]中一致性理论更加广义化的形式:
定理1。假设 表示真实数据分布的密度,
表示生成器 G 产生的数据分布的密度。
和
是可微的固定函数
和真实的或生成的数据分布的函数组合,并且
鉴别器的变换输入。对于固定的
,最优鉴别器由下面的公式得出
对于所有的 。在这种情况下,基于公式(4)得到的最优
当且仅当所有
时
。
附录中提供了定理的证明。从该定理,我们得出结论:特征投影器 及其相关的鉴别器
促使生成器沿着
的边缘匹配真实分布。因此,在收敛时,
在特征空间中匹配生成数据的分布与真实数据的分布。当使用随机数据增强时[^32],在确定投影
之前,该定理也成立。
3.2 模型概述
在预训练的特征空间中投影和训练为问题开辟了新的领域。本节提供一个通用系统的描述,随后是对每个设计选择进行的大量的消融实验。由于我们的特征投影会影响鉴别器,所以我们在本节集中讨论 和
,并将生成器架构的讨论推迟到(Sec05)。
多尺度鉴别器(Multi-Scale Discriminator)。我们以一定的分辨率()从预处理特征网络
的四个层
中获得特征。将单独的鉴别器
在层
与特征相关联。每个鉴别器
在每个卷积层使用具有谱归一化的简单卷积结构[51]。如果所有鉴别器在相同的分辨率($4^2$)输出分对数将会有更好的性能。因此,我们对于低分辨率的输入可以使用更少的下采样块。按照惯例,我们对所有的分对数求和来计算总损失。为了使生成器能够通过检测,我们对所有鉴别器的损失求和。更加复杂的策略[1][^18]并没有提高我们实验的性能。
随机投影(Random Projection)。我们观察到更深层的特征也明显更难覆盖,在(Sec04)的实验中也得到了证明。我们假设鉴别器可以只关注特征空间中的一个子集,而完全忽略其他部分。在更深的层、更多语义的层上,这个问题可能具有突出的表现。因此,我们提出了两种不同的策略来淡化显著特征,鼓励鉴别器平等地使用所有的可用信息。这两种策略的共同之处在于,它们使用固定的、可微的随机投影来混合特征,即在随机初始化之后,这些层的参数不被训练。
跨通道混合(Cross-Channel Mixing,CCM)。根据经验,我们找到两个需要的属性:
- 随机投影的信息应该保留,从而充分利用网络
的表示能力;
- 随机投影不应该是很容易可逆的。
最简单的跨越通道的混合是 的卷积。一个
的卷积的输入与输出通道的数目相同,它是排列的泛化[38],并且结果保存了输入的信息。在实践中,我们发现更多的输出通道导致更好的性能,因为映射保持了单射,因此信息被保留。Kingma等人[38]初始化卷积层时使用随机旋转矩阵作为优化的起始点,而这个操作在我们的实验中没有改善 GAN 的性能(参见附录),可讨论的是因为它与第二条属性有冲突。因此我们先和 Kaiming 初始化卷积层的权重,再随机地初始化卷积层的权重。我们应用这个随机投影在四个尺度每一层,并且前馈变换后的特征到鉴别器(详见图2)。
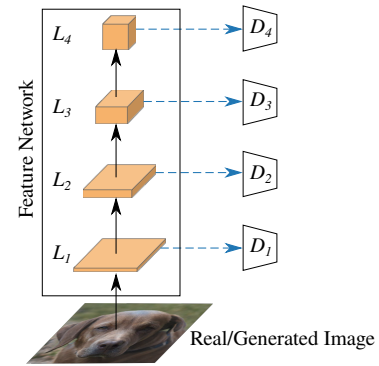
图2:CCM(蓝色虚线箭头)使用随机权重的 卷积。
交叉尺度混合(Cross-Scale Mixing,CSM)。为了强化特征通过尺度混合,CSM 使用 卷积和双线性上采样扩展了 CCM,产生了 U-Net[^65]结构(参见图3)。然而,我们的 CSM 专人相比基本的U-Net更简单:我们仅使用单个卷积层在每个尺度。对于 CCM,我们使用 Kaiming 初始化所有权重。
预训练特征网络(Pretrained Feature Network)。我们在不同的特征网络上进行了消融实验。
- 我们研究了不同版本的 EfficientNet,这种网络允许直接控制模型的大小及对应的性能。EfficientNet 是基于 ImageNet 上训练的图像分类模型,并且设计用于提供良好的精度与计算的平衡。
- 我们使用了不同尺度的 ResNet。为了分析 ImageNet 特征(Sec 4.3)的依赖,在4亿个成对的“图像-文字”数据集上,我们还考虑了 R50-CLIP[^60],它是一个使用成对的语言-图像对象优化的 ResNet。
- 我们使用一个视觉变换架构(Vision Transformer Architecture,ViT-Base)[^14],及其有效的后续(DeiT-small 蒸馏模型)[^78]。我们没有选择 Inception 网络[^76]是为也避开其与评价指标 FID[^23]的强相关性。在附录中,我们还评价了几个神经网络和非神经网络的指标去排除相关性。这个附加的指标反应了从 FID 中获得的地位。
后续,在与最先进的技术比较之前,我们实施了合成消融研究去分析在投影 GAN 模型中每个成分的重要性和最佳配置。
Sec04 消融研究
为了确定鉴别器、混合策略和预训练特征网络的最佳配置,我们 LSUN-Church 数据集上[^84]进行了实验,这个数据集是中等尺度(12万张图像),并且有合理的视觉复杂度,使用的分辨率为 个像素。对于生成器
,我们使用 FastGAN[^49]的生成器架构,它是由多个上采样块组成,每个块都带有额外的跳接层激励块。使用 Hinge 损失[^47],我们训练的批大小为64,直到1百万个真实图像被展示给鉴别器,这对于
的收敛数据量是足够的。如果没有特别说明,我们在本节中使用 EfficientNet-Lite1[77]特征网络。我们发现鉴别器的增强[32][79][89][90]能够同样地改善所有方法的性能,并且能够满足要求达到最先进的性能。我们利用可微的数据增强[89],这个方法与 FastGAN 生成器的结合可以产生最佳的结果。
| 鉴别器 | rel-FD1 ↓ | rel-FD2 ↓ | rel-FD3 ↓ | rel-FD4 ↓ | rel-FID ↓ |
|---|---|---|---|---|---|
| 没有投影 | |||||
| on |
0.56 | 0.23 | 0.31 | 0.55 | 。066 |
| on |
0.35 | 0.21 | 0.23 | 0.47 | 0.53 |
| on |
0.42 | 0.26 | 0.28 | 0.64 | 0.90 |
| on |
0.46 | 0.34 | 0.38 | 0.79 | 1.15 |
| on |
0.95 | 0.67 | 0.71 | 1.19 | 1.99 |
| on |
2.14 | 1.41 | 1.18 | 1.99 | 3.46 |
| on |
10.92 | 5.74 | 2.56 | 2.79 | 5.08 |
| 感知机 |
2.98 | 1.76 | 1.20 | 1.89 | 2.73 |
| CCM | |||||
| on |
0.27 | 0.21 | 0.26 | 0.50 | 0.59 |
| on |
0.27 | 0.18 | 0.21 | 0.41 | 0.48 |
| on |
0.31 | 0.25 | 0.24 | 0.54 | 0.67 |
| on |
0.53 | 0.34 | 0.34 | 0.59 | 0.77 |
| 感知机 |
5.33 | 3.06 | 2.14 | 1.09 | 4.77 |
| CCM+CSM | |||||
| on |
0.34 | 0.25 | 0.19 | 0.35 | 0.44 |
| on |
0.21 | 0.18 | 0.16 | 0.27 | 0.31 |
| on |
0.41 | 0.26 | 0.17 | 0.23 | 0.29 |
| on |
0.26 | 0.16 | 0.13 | 0.16 | 0.24 |
| 感知机 |
2.53 | 1.37 | 0.89 | 0.43 | 2.13 |
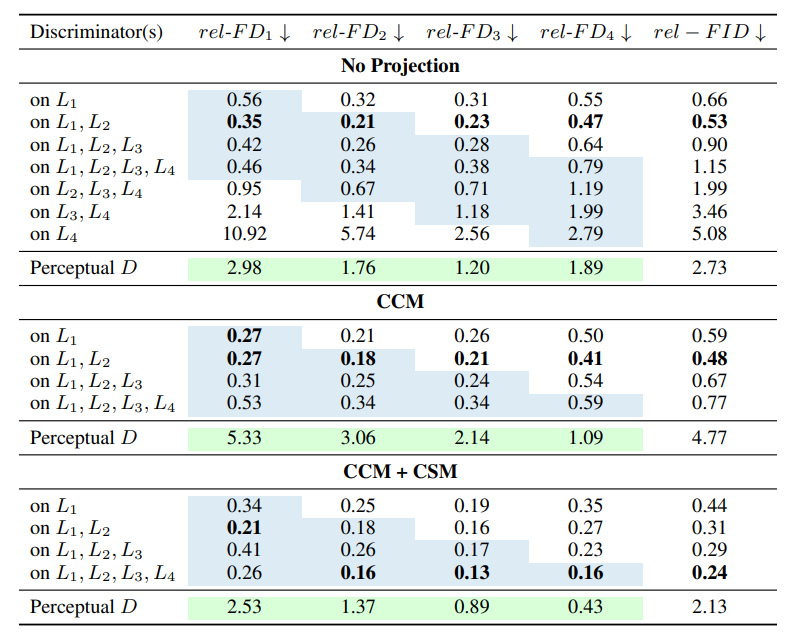
表1:特征空间 Frechet 距离。我们的目标是找到鉴别器和随机投影的最佳组合来拟合特征网络 的分布。我们在网络
的不同层(
)上展示了 LSUN-Church 的5万个生成图像和真实图像之间相对
。对带有标准的单个 RGB 图像鉴别器的模型使用基线 Frechet 距离对
进行归一化。我们报告了四个层(
)的
,层都来自于 EfficientNet(层都是从浅到深),还报告了相关的 Frechet Inception 距离(FID)[23]。请注意,$rel-FD_i$不能在不同的特征空间之间进行比较,即只有列内比较才有意义。蓝色高亮的层通过独立鉴别器进行监督。绿色高亮对应感知机器[75],这个标记在所有的特征图中都立刻应用了。
4.1 哪些特征网络层的信息量更大
我们首先研究的是多尺度鉴别器之间的相关性。对于这个实验,我们没有使用特征混合。为了衡量 与特定的特征空间的匹配程度,我们在按层
来描述的
的空间池化特征上采用了 Frechet 距离(FD)[^17]。跨越不同特征空间的
是不能直接比较的。因此,我们使用了标准的 RGB 鉴别器训练了一个 GAN 的基线,在每一层记录
,通过片段
量化相关的改进。我们也研究了感知机鉴别器[^75],其中特征图被卷入相同鉴别器的不同层中用于预测一个单个的分对数。
表1(非投影,No Projection)展示了两个鉴别器比一个效果好,并且改进了常用 RGB 的基线。令人惊讶的是,在深层添加鉴别器反而会伤害性能。我们可以得出结论这些更具有语义的特征不能很好地反应直接的对抗损失。我们还在原始图片的不同尺寸上对鉴别器进行实验,但是没有找到超参数和结构的设置能够改善单个图像的基线。删除浅层特征的鉴别器会降低性能符合我们的预期,因为这些层包含了原始图像的大部分信息。相似的影响在特征翻转[^16]上也能观察到,即层越深,输入重建就越难。最后,我们还观察到独立的鉴别器显著地好过感知器鉴别器。
4.2 怎样才能最好地使用预训练特征?
根据上一节的见解,我们的目标是改善深度特征的使用。对于这个实验,我们仅仅研究了在高分辨率下包含鉴别器的配置。表1(CCM和CCM+CSM)展示了两种混合策略。CCM适度地减少了所有配置的 FD,证明了我们的假设,即混合通道为生成器产生了更好的反馈。当加入 CSM 时,我们在所有配置上获得了另一个显著的改善。特别是 在更深的层上显著地减少,证明 CSM 在利用深层语义特征上的有效性。有趣的是,我们观察到混合四个鉴别器可以获得最好的性能。一个感知机鉴别器再次弱于多重鉴别器。我们还注意到,在合成原始图像的问题上,通过独立的鉴别器或者CCM或者CSM总会产生更差的性能。这个失败建议使用投影对抗优化来朴素地组合非投影会损害训练的动态性。

表2:预训练特征网络研究。我们使用不同的预训练特征网络训练投影 GAN,发现紧凑的 EfficientNet 比 ResNet和Transformer都好。
4.3 哪个特征网络架构更加有效?
使用由上述实验确定的最佳设置(最佳设置来自于具有四个鉴别器的 CCM+CSM 的实验),我们研究了用于投影 GAN 训练的各种感知机特征网络结构的有效性。为了确保整合,也为了更大的架构,我们训练了 1000 万个图像。表2报告了在 LSUN-Church 上得到的 FID。令人惊讶的是,我们发现与 ImageNet 的准确性没有相关性。相反,我们观察到较小的模型(如:EfficientNets-lite)的 FID 越低。这一观察表明,更加紧凑的表示是有益的,并且还同时减少了计算开销,从而减少了训练时间。R50-CLIP 略优于 R50,说明不需要 ImageNet 的特征就能实现低 FID。为了保证完整性,我们还使用随机初始化的特征网络进行了训练,然而这些特征网络收敛到更高的 FID 值(参见附录)。接下来,我们使用 EfficientNet-Lite 作为我们的特征网络。
Sec05 与最先进模型的比较
本节进行了全面的分析,展示了与最先进模型的对比,证明了 投影GAN 的优势。我们的实验被分成三个部分:
- 收敛速度和数据效率的评估(5.1)
- 比较大规模基准数据集(5.2)和小规模基准数据集(5.3)。
我们涵盖了各种各样的数据集,有不同大小的(几百到几百万个样本)、不同分辨率的( 到
)和不同的视觉复杂性的(剪贴画、绘画和照片)。
评估协议。我们使用 Frechet Inception 距离(FID)[23]来评估图像的质量。遵循[33][^34],我们报告了5万个生成的与所有的真实图像之间的 FID。我们为每种方法选择具有最佳 FID 的快照。除了图像质量外,我们还包括了一个评估收敛性的指标。就像在[^32]中一样,我们基于向鉴别器展示的真实图像数目(Imgs)来评估训练的进度。在整个训练中,我们报告了模型要达到最佳FID的5%的值时所需要的图像的数量。在附录中,我们还报告了在 GAN 的文献中出现过,但是很少作为基准的指标:KID[4]、SwAV-FID[53]、准确率和召回率[66]。除非另有说明,我们遵循[26]的评估协议以推动公平的比较。具体来说,我们比较了所有的方法,图像的数目是给定的、相同的固定数量(1000万)。在这种设置下,每个实验大致需要100~200个 Nvidia V100 GPU 小时,更多细节参考我们的附录。
基线。我们使用 StyleGAN2-ADA[32]和FastGAN[49]作为基线。依照样本质量区分,StyleGAN2-ADA在大多数数据集上是最强的模型,而 FastGAN 在训练速度方面表现出色。我们实现了我们的投影GAN,还基于 StyleGAN2-ADA 作者提供的代码实现了基线。对于每个模型,我们运行了两种数据增强:可微数据增强[89]和自适应鉴别器增强[32]。我们为每个模型选择了性能更好的增强策略。
对于所有的基线和数据集,我们通过x-翻转进行了数据增强。对于所有的实验,投影GAN使用相同的生成器和鉴别器架构,以及训练的超参数(学习率和批处理大小)。对于高分辨率图像生成,生成器中包含了额外的上采样块,以匹配所需要的输出分辨率。我们仔细地调整两个基线的所有超参数以获得最佳结果:我们发现 FastGAN 对于批处理大小很敏感;而 StyleGAN2-ADA 对学习率和 惩罚很敏感。附录记录了我们在每个实验中使用的附加的实现细节。
5.1 收敛速度和数据效率
遵循[26][85],我们在图像分辨率为 像素的 LSUN-Church 数据集上和 7万张图像的 CLEVR 数据集[^29]上分析了投影 GAN 的训练属性。在本节中,我们在必要时候也训练过多于 1000万图像的数据集,因为我们希望了解其收敛性质。
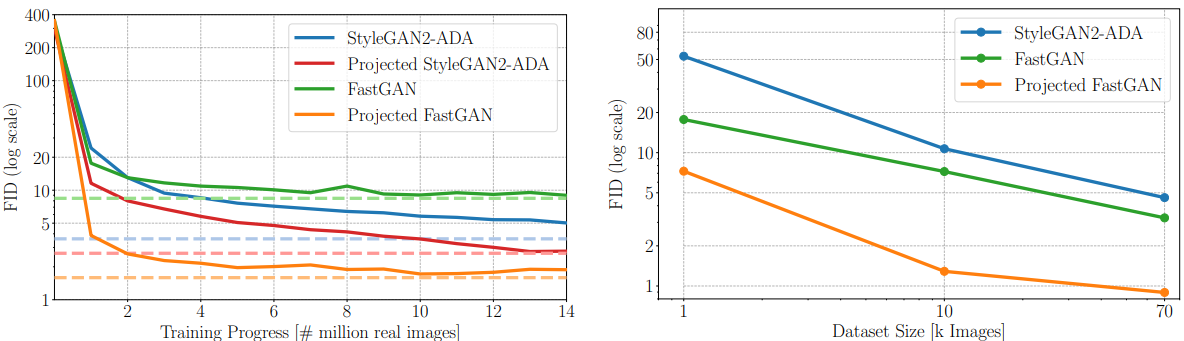
图4:训练性质。左:在 LSUN-Church 数据集上,投影FastGAN的FID(110万图像)就超过了 StyleGAN2 的最佳FID(8800万图像)。右:在 CLEVR 的 1千和 1万样本子集上,投影FastGAN也显著改善了FID值。
收敛速度。我们应用投影GAN训练 StyleGAN2 的基于风格的生成器和 FastGAN 的包含单个输入噪声微量的标准生成器。如图4所示(左),FastGAN收敛更快,但是稳定在高 FID。StyleGAN2 收敛更慢(8800万图像),但是达到更低的 FID。投影GAN训练改善了两个生成器。特别是FastGAN,同时改善了收敛速度和最终的FID;但是对于StyleGAN2的改善效果就没有那么显著了。令人注目的是,投影FastGAN 仅在110万图像时就达到了StyleGAN2在8800万图像时得到的最佳FID。反应时间也从5天变成了3个小时。因此,从现在开始,我们使用FastGAN的生成器,并将这种模型简称为投影GAN。

图5:在 像素的 LSUN-Church 数据集上的训练过程。展示的是覆盖
个图像后固定噪声向量
的输出样本。从上到下:FastGAN、StyleGAN2-ADA、投影GAN。
图5展示了在 LSUN-Church 数据集上固定噪声向量输出的样本。对于FastGAN和StyleGAN来说,纹理的Patch会逐渐变成一个整体结构。对于投影GAN,我们直接观察到结构的出现,随着时间的推移,结构变得更加细致。有趣的是,投影GAN的隐空间表现得动荡,即对于固定的
,图像在训练过程中经历了显著的感知变化。在非投影案例中,这些变化则更加平缓。我们假设这种由鉴别器诱使的振荡性相比传统的 RGB 损失提供了更多的语义反馈。这样的语义反馈可能在训练阶段引入更多的随机性,从而交替改善收敛性和性能。我们还观察到在整个训练阶段,鉴别器的有符号的实分对数保持在相同的水平(参见附录)。平稳的有符号的分对数表明鉴别器没有受过拟合的影响。
样本效率。预训练模型的使用通常都能改善样本的效率。为了评估这个性质,我们还创建了 CLEVR数据集(7万图像)的两个子集:(分别抽取的)1千图像和1万图像。如图4(右)所示,我们的投影GAN显著地改善了所有数据集分割的两个基线。
5.2 大型数据集
除了 CLEVR 和 LSUN-Church,我们还在另外三个大型数据集上以各种最先进的模型作为基准对投影GAN进行了测试,这三个数据集是:LSUN-Bedroom[84](300万室内卧室场景)、FFHQ[77](7万脸部图像)和Cityscapes[9](2.5万从汽车上捕捉的驾驶场景)。对于所有的数据集,我们使用的图像分辨率都是$256^2$像素。因为Cityscape和CLEVR图像不是$1:1$的比例,我们将它们的尺寸变化为$256^2$用于训练。除了StyleGAN2-ADA和FastGAN模型,我们还比较了SAGAN[86]和GANsformers[^26]。所有的模型训练1000万图像。对于大型数据集,我们还报告了StyleGAN2训练图像的数目(超过1000万图像),和在以前的文献中获得的最低的FID值(记作 StyleGAN2*)。在附录中,我们报告了9个更大的数据集的结果。
表3说明在所有的数据集上,投影GAN在FID值方面优于所有最先进的模型。例如:在LSUN-Bedroom上,它实现了FID值为1.52,相比之下,该设置下以前最好的模型GANsformers为6.15。投影GAN获得最先进的FID值的速度非常快,例如:在LSUN-Church上,它在110万图像后就实现了3.18的FID值。StyleGAN2在8800万图像后获得先前的最低FID值3.39,是投影GAN所需图像的80倍。如表3所示,对于所有其他大型数据集上也实现了的加速。有趣的是,当在FFHQ(3900万图像)上训练更长时间时,我们发现投影GAN进一步改善FID值为2.2。请注意,所有五个数据集都表示不同场景中非常不同的对象。这个证明选择不同的数据集其性能增益也是稳健的,尽管特征网络仅在 ImageNet 上进行了训练。值得注意的是,主要的改进是基于样本多样性,如我们在附录中报告的那样。多样性的改进在大型数据集上是非常显著的,例如:LSUN-Church 的图像保真度与 StyleGAN 的相似。
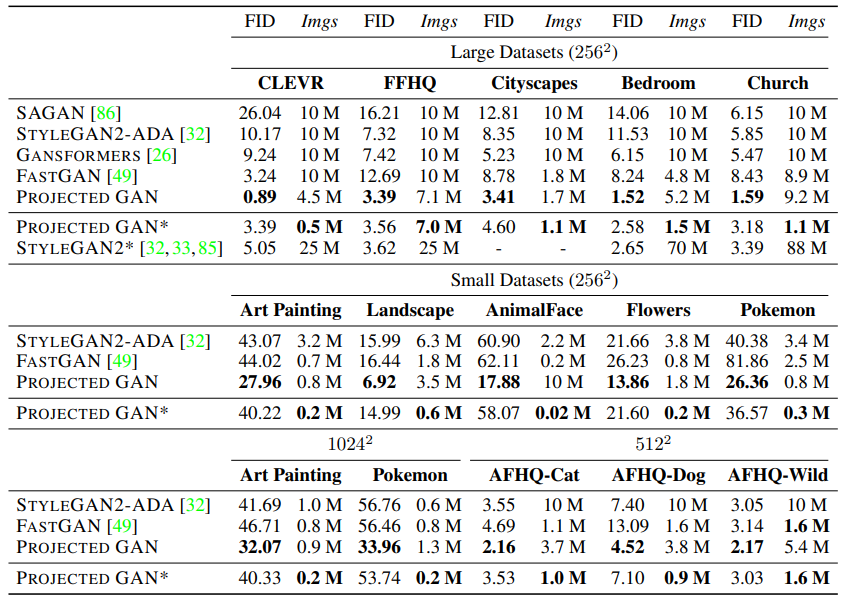
表3:量化结果。投影GAN 报告了超越最先进模型的点。StyleGAN2报告了在先前的文献中获得的最低的FID值,只要训练时间足够长。
5.3 小型数据集
为了进一步评估我们的方法在小样本设置下的性能,我们基于几个小型数据集比较了StyleGAN2-ADA和FastGAN,这几个小型数据集是:WikiArt(1000图像,wikiart.org)、Oxford Flowers(1360图像)[^56]、风景照片(833图像, flickr.com)、AnimalFace-Dog(389图像)[^72]和Pokeman(833图像, pokemon.com)。此外,我们还报告了Pokeman和Art-Painting的高分辨率版本()的结果。最后,我们还基于分辨率
评估了AFHQ-Cat、AFHQ-Dog和AFHQ-Wild[7]。AFHQ数据集对于每个类别(猫、狗、野生动物)包含大约5000个特写图像。我们没有分发这些数据库的版权,但是我们提供了URL以满足复现,类似于[49]。
如表3所示,在所有的数据集和所有的分辨率上,投影GAN超越了所有的基线。值得注意的是,我们的模型在观察了不到60万张图像后,在所有的数据集上(分辨率为
图6:真实样本(上一行)与投影GAN的样本(下一行)。数据库(从上左到下右):CLEVR(), LSUN-Church(
), Art Painting(
), Landscapes(
), AFHQ-wild(
), Pokemon(
), AFHQ-dog(
), AFHQ-cat(
).
Sec06 讨论现在与展望未来
虽然我们大所有数据集上都获得了很低的FID,但是我们也发现了两个系统性的失败案例:如图7中描述的,AFHQ中观察到的悬空头。在少量样本中,图像质量很高,但是在模糊或者平淡的背景上看起来像剪贴画。我们假设当一个突起的物体已经被的描绘出来时,生成一个真实的背景与图像合成就不那么重要了。这个假设来源于这样一个事实,即我们使用图像分类模型进行投影时,应用在去除了背景的物体图像时模型的精度仅略微降低[^83]。在 FFHQ 上,投影GAN有时也会产生错误的比例和不自然的物体,甚至在最先进的FID时,参见图8。

图7:悬空头

图8:FFHQ中的非自然物体
就生成器而言,StyleGAN的调优更具挑战性,因为其无法从投影训练中获得好处。FastGAN的生成器的优化速度很快,但同时在隐空间的某些部分产生了不真实的样本————这个问题可以通过类似于StyleGAN映射网络来解决。因此,我们推测将两种架构的优势结合在一起,再加上投影GAN,可能会进一步提高性能。此外,我们对不同的预训练网络的研究表明,有效的模型特别特别适合投影GAN的训练。深入探索这种联系,一般来说,确定所需要的特征空间的性质打开了令人兴奋的新研究机会。最后,我们的工作提高了生成模型的效率。更加高效的模型降低了生成真实图像所需要的计算工作量。更低的门槛加速了生成模型的恶性使用(如:深度伪造),同时也使该领域的研究民主化。

