自动摘要: |版本号|作者|发布日期|修订| ||||| |V1.0.0|[@](https://www.yuque. ……..
| 版本号 | 作者 | 发布日期 | 修订 |
|---|---|---|---|
| V1.0.0 | @叶子扬 | 初始版 | |
| V1.0.1 | @张新霞 | 2021年11月24日 | 支持14颗牙 |
| V1.0.2 | @张新霞 | 2021年12月03日 | 修复V1.0.1缺陷 |
| V2.0.0 | @Sindre Yang | 开发V2.0.0基础版 | |
| V2.0.1 | @Sindre Yang | 开发V2.0.1修正版 | |
| V2.1.1 | @Sindre Yang | 开发V2.1.1基础版 | |
| V2.2.1 | @Sindre Yang | 开发V2.2.1基础版 | |
| V2.2.2 | @宋阳 | 实现8颗牙分牙 | |
| V2.2.3 | @宋阳 | 实现9颗牙分牙 | |
| V2.2.4 | @宋阳 | 实现对称分牙 | |
| V2.3.0 | @宋阳 | 齿龈分离,牙齿分区,提取后磨牙(包括智齿)三分类,提取前磨牙和尖牙三分类,提取切牙四分类; | |
| V2.3.1 | @宋阳 | 展会特别版 | |
| V2.3.2 | @宋阳 | 月底增强训练版 | |

V1.0.0
特点:
- 在20份牙齿模型上,基于MeshSegNet实现自动分牙;
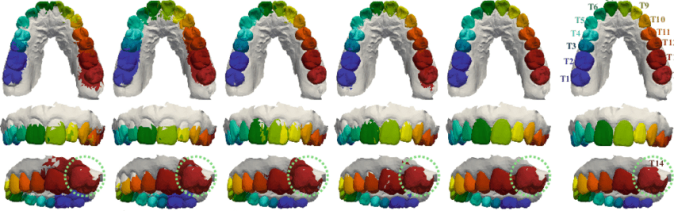
V1.0.0-后处理优化V1.0.0
特点:
- 尝试通过聚类,knn,svm,条件随机场进行二次分割
缺陷:
- 噪声太多
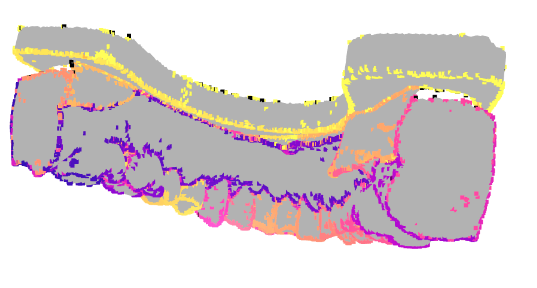
V1.0.0-后处理优化V1.1.0
特点:
- 点云边检测后使用数次RANSAC去除不需要的平面;输入其他组给的网格特征点数据,使用数次RANSAC去除不需要的平面;合并两次实验的点云数据;
- 对原始牙模点云数据做平均曲率计算,记录信息,并与前面的点云数据合并;
- 建立kd-tree,使用最近邻扫描所有2部分的数据;若曲率小于0(凹陷,需要调参得到合适阈值),保存特征集合的点;保存点初步认为最大拟合了颈缘线
总结:
- 个人觉得用条件随机场可以提高精度,但最根本的方法是重新训练适合自己模型,训练量太少
V1.0.1
特点:
- 支持14颗上下颌牙模
- 支持对上下颌牙齿模型进行区分
- 添加C++部署代码
V1.0.2
修正:
- 修复V1.0.1版本神经网络模型不匹配问题
发布:
V2.0.0
修正:
- 重新优化训练代码,cpu不再参与处理,集中在GPU处理。
- 去除距离矩阵计算,移植到模型内部计算。
- 输入去除两个距离矩阵输出,简化到面片(顶点)+面片中心+面片法线共15维度合并输入
特点:
- 只支持14颗牙颌。
- 总体输入建议为1w面片,牙齿面片与牙龈面片比建议为:8:2
- 上颌loss为0.035,下颌loss为0.049,整体测试平均精度为0.91。
- (上颌在400份linux上训练,下颌在1330份上windows训练),原因:预处理数据占用约500G空间,空间不足。
- 每份通过仿射变换增强30次。
- 每轮迭代约7分钟,共需迭代200轮,预计需要24小时。
- 由于服务器不知明的原因重启,还在以0.001精度提升中
- 专有模型(pt)转换成部署模型(onnx),精度损失为约0.0001
- 输入建议为【1(输入个数,可变),15(面片(顶点)+面片中心+面片法线,可变),10000(面片数,可变)】
- 输出为【1(输入个数,可变),10000(面片数),15(概率值,取最大值即预测值)】
推理速度:
- 个人主机:AMD 5800H,推理1份,冷启动
└─ 3.820 总计 ├─ 2.462 CPU推理时间(因为内置 ├─ 1.057 简化用时 ├─ 0.153 数据转换用时 └─ 0.045 网格读取用时
实验总结:
- 概要:
- 类别种类越低,精度越高。
- 异常数据会造成样本不平衡问题,因为14颗牙占比为80%以上,16颗为10%,其他部分残缺为10%。
- 如果分割局部面片会提升精度(即识别牙上特征面片,而不是识别整个牙)
- 超过1w面片训练,会提升精度,但用户需配备16G内存或6G显存。
- 实验记录:
- 14-10类数据,设定类别为15类,精度下降到为89%。–3w份
- 16-10类数据,设定类别为17类,精度下降到为80%。–3w份
- 32-20类数据(上下颌混合),设定类别为33类,精度下降到为77%。–3w份
- 2类数据(牙龈,牙列),设定类别为2类,精度为99.98%—100份数据
- 7类数据(残缺牙弓),设定类别为8类,精度为98%—100份数据
- 14类数据,设定类别为15类,精度下降到为96%。–3w份
V2.0.1
修正:
- 在完整数据上进行增强训练;
- 修改部分参数,使得准确率在96%;
V2.1.1
特点:
- 在V2.0.1基础上增加14颗随机缺少一颗的数据集。
功能:
- 支持残缺牙识别,
缺陷:
- 但限制在14颗以内,缺失一颗表现较优。
- 较V2.0.1精度损失为0.005%。
- 对特殊“奇形怪状”牙识别较差,因为训练数据牙齿都比较整齐。
V2.2.2
特点:
- 在V2.1.1基础上增加9-16颗数据。
功能:
- 支持9-16颗牙识别
缺陷:
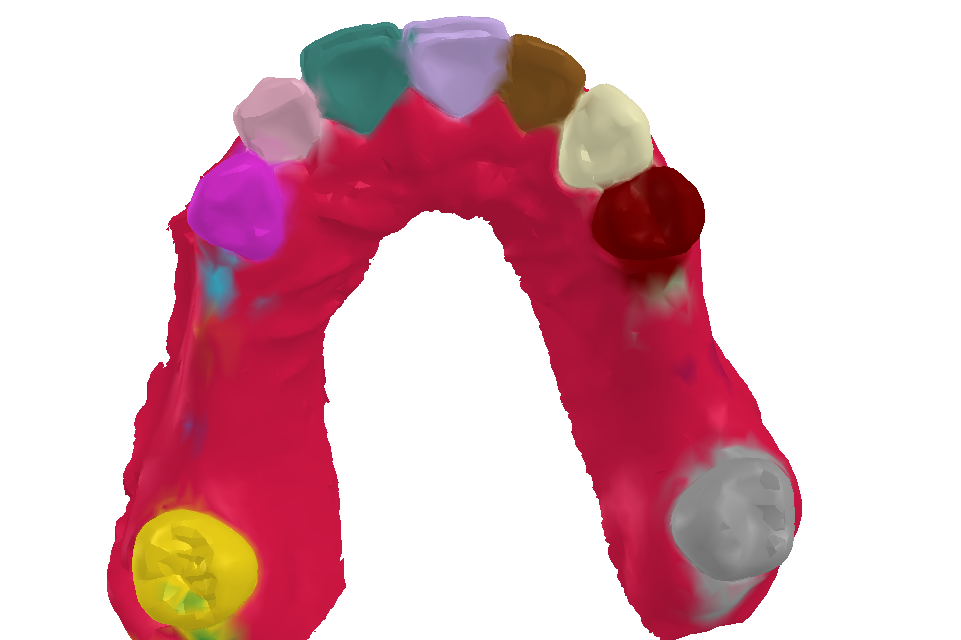
- 牙龈突起出可能错误识别,需后处理。
- 右边最后一颗牙可能牙位不准,需通过邻近关系二次修正。
V2.2.3
特点:
- 在V2.0.0基础上增加14颗数据。
功能:
- 支持14颗牙对称识别;
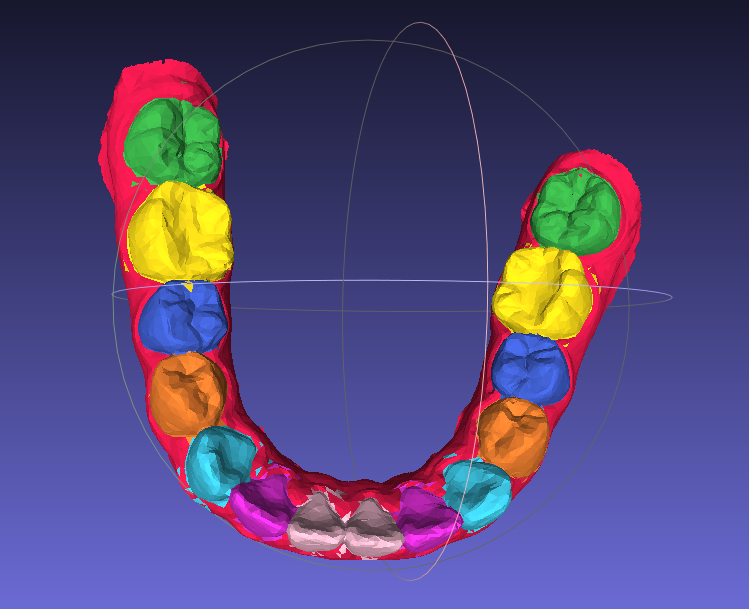
缺陷:
- 不支持16颗牙;
V2.2.4
特点:
- 重构数据处理代码,对16颗牙齿进行8分类,牙龈1类,共计9类;
- 未优化前准确率在,上颌96%,下颌95%;
- 增加16颗数据。
功能:
- 支持16颗牙对称识别;

V2.3.0
特点:
- 分牙5模型分别为:齿龈分离,牙齿分区,提取后磨牙(包括智齿)三分类,提取前磨牙和尖牙三分类,提取切牙四分类;
- 未优化前准确率:齿龈分离95.8%,牙齿分区99.3%,后磨牙分类98.1%,前磨牙和尖牙99.5%,切牙99.0%;
- 齿龈分离模型准确率达到96.5%,提高了未裁剪牙龈数据的准确率。
缺陷:
- 对牙龈未裁剪的数据效果不好。
V2.3.1
特点:
- 针对10份数据(包括测试不好及展会数据)进行增量训练,精度为0.97。
- 注意优化强度调试,需相关集成人员针对展会模型进行微调
- 模型位置在钉钉-项目文件内,直接替换AI模型即可,其他无需改动。
V2.3.2
特点:
- 上颌准确率92.2%
- 下颌准确率96.9%
- 加入展会数据训练,丰富了数据多样化,下颌模型比上颌准确率高、训练耗时少;
缺陷:
- 上颌模型对展会数据不友好;

