自动摘要: 变更记录 >记录每次修订的内容,方便追溯。 |版本号|修订内容|发布日期| |||| |1.1|解决牙花生成细节问题 ……..
变更记录
记录每次修订的内容,方便追溯。
| 版本号 | 修订内容 | 发布日期 |
|---|---|---|
| 1.1 | 解决牙花生成细节问题 | 2022-02-01 |
| 1.0 | 发布全冠生成基础版,达到基本需求 | 2021-11-10 |
1. 背景介绍
1.1 业务背景
对本次项目的背景以及目标进行描述,让产研团队了解本需求的价值和收益。
- 在牙科行业,技师需要接受数年的培训才能设计出人造牙冠,用于恢复缺失牙齿的功能和完整性。每个牙冠都 需要为每位患者量身定制,即使有计算机辅助设计软件的支持,也需要专业人士在时间和体力付出巨大代价。
- 我国牙科行业在AI领域探索相对较少,开源方案较少;
- 牙科涉及三维行业,涉及数学理论较深,较广,挑战众多
1.2 业务场景
解释业务的服务场景和商业价值。
| 场景/商业模式 | 商业价值
|
| — | — |
| 标准服务 | 提供基础服务,包括售前咨询、售中演示、售后服务 |
| 个性化服务 | 提供个性化定制和本地私有化部署 |
| 商业化解决方案 | 提供智能 AI 解决方案,涉及医患沟通,医技沟通 |
2. 算法概述
2.1 算法定位
在牙科修复场景下,提供自动生成能力,服务口腔医生平台或软件的一种解决方案。
- 大幅度提升技师设计牙冠时间;
- 解决因技师经验造成的设计不足;
- 提供牙科修复统一的解决方案;
- 减少医患沟通成本;
2.2 服务对象
牙科行业研发者,口腔技师,口腔医生,三维算法从业者;
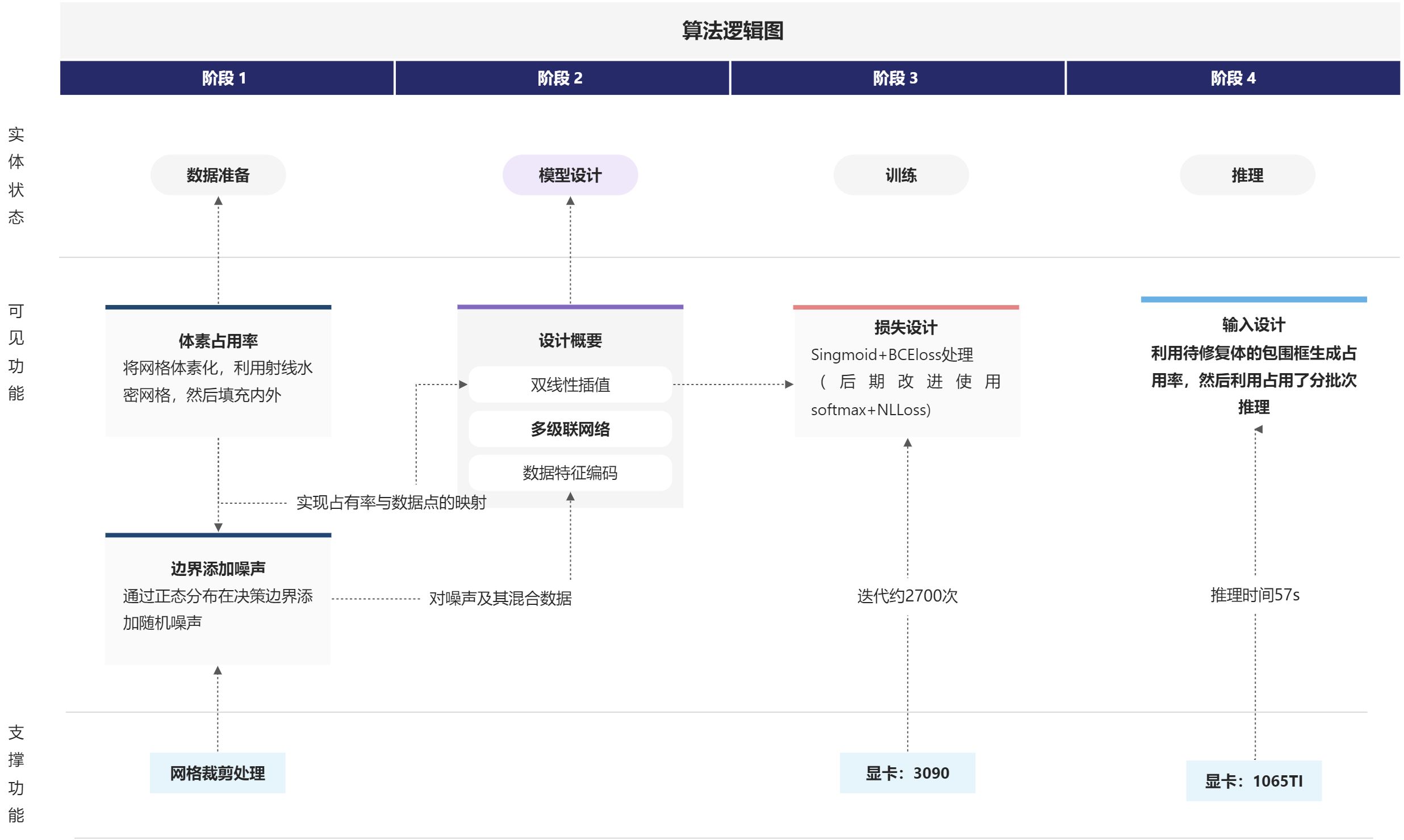
2.3 算法逻辑
2.4 理论基础
作者:Neil Li链接:https://www.zhihu.com/question/493693595/answer/2181734554来源:知乎著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
2.4.1 隐式神经表示法是什么
隐式神经表示法(Implicit Neural Representations)是一种将各种信号参数化的新方法。传统的信号表示通常是离散的-例如,图像是像素的离散网格,音频信号是振幅的离散样本,三维形状通常被参数化为体素、点云或网格。相反,隐式神经表示将信号参数化为连续函数,该函数将信号域(即,坐标,如图像的像素坐标)映射到该坐标处的任何位置(对于图像,为R、G、B颜色)。当然,这些函数通常上是不可处理的——不可能“写下”将自然图像参数化为数学公式的函数。因此,隐式神经表示通过神经网络去靠近该“自然表示”函数。
对3D物体表示方法有以下几种方式,分别是基于voxel(体素),基于点云,基于mesh和基于volume的方法,其中前三种方法的问题是都是离散的,这就造成了它们都是不可微的;而最后的一种方法则是连续可微的方程。
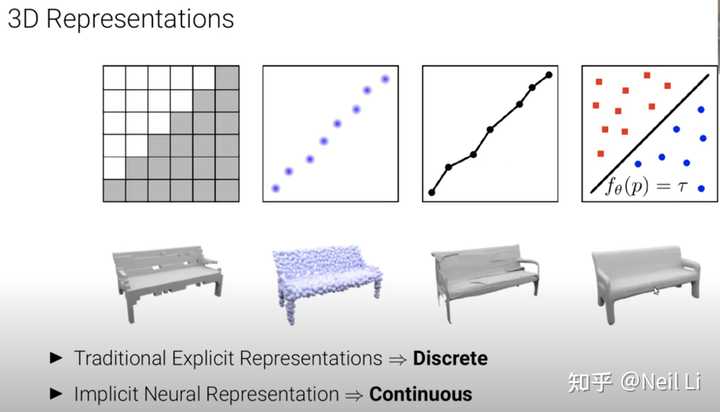
2.4.2 隐式神经表示法有几个好处
首先,它们不再与空间分辨率耦合,例如,图像与像素数耦合的方式。这是因为它们是连续函数!因此,参数化信号所需的内存与空间分辨率无关,并且仅与隐藏的信号的复杂性成比例。换言之,隐式表示具有“无限分辨率”——它们可以以任意空间分辨率进行采样。
这对于许多应用(如超分辨率)或三维和更高维的参数化信号(其中内存需求随着空间分辨率的提高而快速增长)非常有用。此外,跨神经隐式表示的泛化相当于学习函数空间上的先验知识,通过学习神经网络权重上的先验知识来实现-这通常被称为元学习,是两个非常活跃的研究领域的一个非常令人兴奋的交叉点!另一个令人兴奋的重叠是神经隐式表示和神经网络结构中对称性研究之间的重叠——首先,创建三维旋转不变性的神经网络结构是创造神经隐式表示旋转不变性生成模型的可行路径。
隐式神经表征的另一个关键承诺在于直接在这些表征空间中操作的算法。换句话说,“卷积神经网络”与对隐式表示的图像进行操作的神经网络是什么?
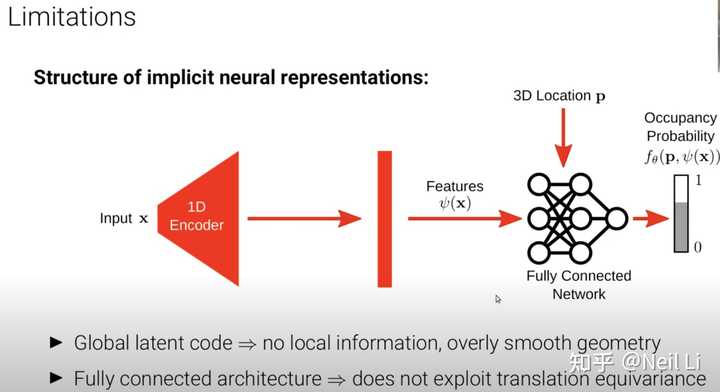
2.4.3 隐式神经表示法的局限性
在实际使用implicit neural representation的时候,会有一些问题,而这些问题则造成了在渲染具有精细结构的物体的时候表现不是很好。

3. 项目排期

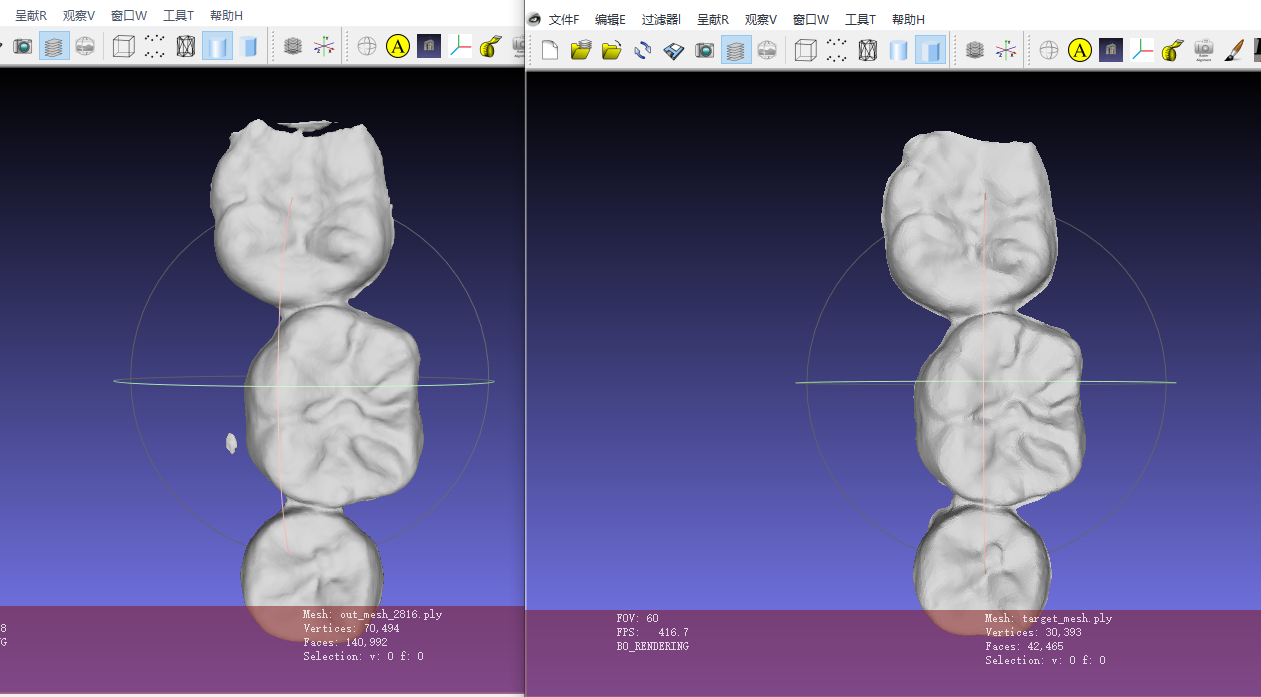
4. 现阶段效果展示
数据来源:南航
5. 现阶段缺陷:
- 存在离群噪声
- 可用连通体去除
- 生成面片过多
- 可使用网格简化
- 控制推理,训练
- 空间位置稍有偏移
- 在南航数据上直接使用ICP可以直接配准
- 提升模型精度后,可能会进一步改善配准问题
6.未来计划
- V32模型继续训练,直到过拟合,对比最优模型的效果是否能够解决现阶段的缺陷
- V128模型训练,直到过拟合,对比最优模型的效果是否比现阶段的效果更好
- V256模型训练,直到过拟合,对比最优模型的效果是否有进一步提升
- 使用全水密模型数据进行训练,尝试效果是否能够满足预期,特别是牙花精度与配准问题
- 使用二颗牙输入,一颗牙输出或者二颗牙输出这种模式进行训练,对比输出模型的效果
- 使用三颗牙输入(邻近两颗与对颌一颗),一颗牙输出或者二颗牙输出这种模式进行训练,对比输出模型的效果
- 使用深度图(Pix2Pix)先生成牙花,再将牙花生成点云,再与输入模型的点云一起进行训练,对比输出模型的效果(可能输出结果的精度更高,泛化性能更强)
- 使用 GAN 生成三维点云(这个想法不太成熟)
- 取消模型中坐标特征,对比效果
- 使用隐函数(IF-Nets)训练模型,用低分辨率(32)输出模型,再使用深度图进一步处理牙花问题,从而加快推理速度
- 代码修改
1. 使用 trainer 类重构代码,使得变量可以内部传递
2. 使用 loss 类重构代码,方便 loss 的修改
3. 使用 PyTorch-Lightning 重构代码,使得训练过程更加简洁

