自动摘要: 修订历史 |时间|版本号|修订人|主要修订内容| ||||| |2023年5月17日|v1.0.0 ……..
修订历史
| 时间 | 版本号 | 修订人 | 主要修订内容 |
|---|---|---|---|
| 2023年5月17日 | v1.0.0 | 杨新 | 初始版本 |
摘要
- 提出一种基于点云学习的自动排牙方法。
- 该方法将牙齿排列任务转换为7D向量预测问题;
- 提供一个针对全牙弓和局部牙齿点云学习的神经网络架构;
- 通过大量试验得到验证,在泛化性方向和质量上显示令人满意得结果;
介绍
不规则的牙齿排列不仅会导致美学问题,还会损害咀嚼的功能。不正确的咬合关系(如:过度咬合或者牙齿拥挤)可能会导致咀嚼障碍,这往往会诱发其他继发性疾病。随着人们对口腔健康的日益关注,对正畸治疗的需求也越来越多。尽管寻求正畸护理的人数正在迅速增加,但是能够满足需求的合格的正畸医生在总体上严重缺乏。目前,正畸治疗涉及繁琐的手工操作,并且培训专业的正畸医生也是一个漫长而且昂贵的过程。此外,诊断和治疗的质量在很大程度上取决于正畸医生的个人技能和经验。因此,有必要开发一个全自动的系统来快速推荐最佳的牙齿排列,以提高正畸治疗计划的质量与效率。
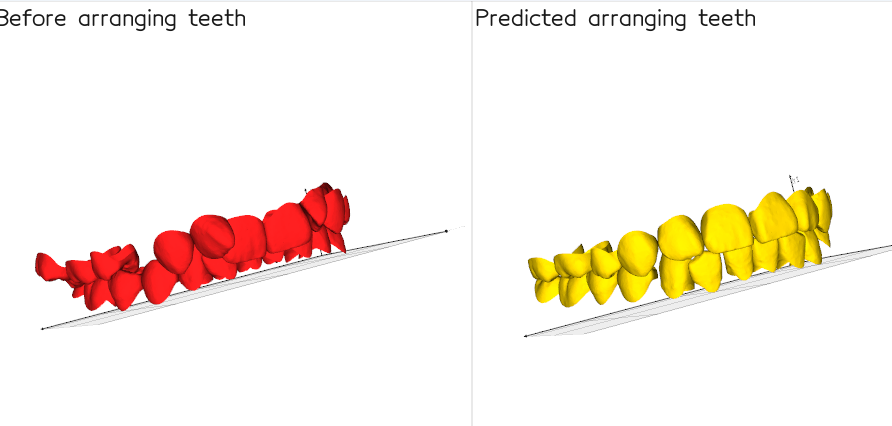
牙齿排列是正畸治疗中必不可少的一步。给定患者的一组位置不良的牙齿,牙齿排列的目标是预测理想的牙齿布局,这个布局作为通过正畸治疗实现的最终排列。为了生成令人满意的排列,需要考虑许多的因素。这使得牙齿排列成为一项复杂的任务,任务结果的质量严重依赖于正畸医生的专业技能和主观判断。
我们提出了一种基于学习的方法,从患者治疗前的初始的不规则的牙齿位置预测最佳治疗目标,从而开发了一种用于正畸治疗的自动牙齿排列方法。我们将牙齿排列任务公式化为一个结构化的7D姿态预测问题,这个问题尚未被计算机视觉领域充分探索。我们的网络旨在通过监督学习来近似表示一种映射关系,这个关系是初始牙齿排列的牙齿输入模型到理想目标姿态的映射。这个网络由五个主要组件构成:
- 用于牙颌特征编码模块;
- 用于单牙特征编码模块;
- 用于牙齿信息编码模块;
- 用于排列信息预测模块;
- 7D位姿预测模块;
总之,当前工作的主要贡献是:
- 我们开发了第一个基于深度学习的自动排牙框架;
- 我们提出了使用一种多维度信息模块,从而为成功地解决由牙齿排列任务引出的结构化姿态预测问题提供关键的上下文信息 。
方法
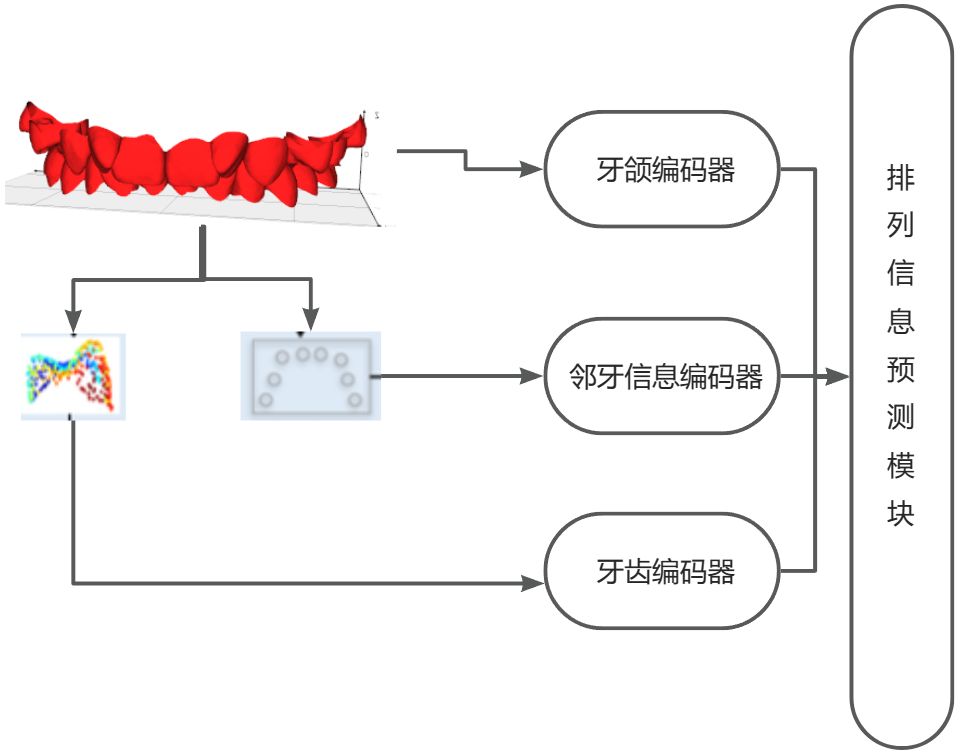
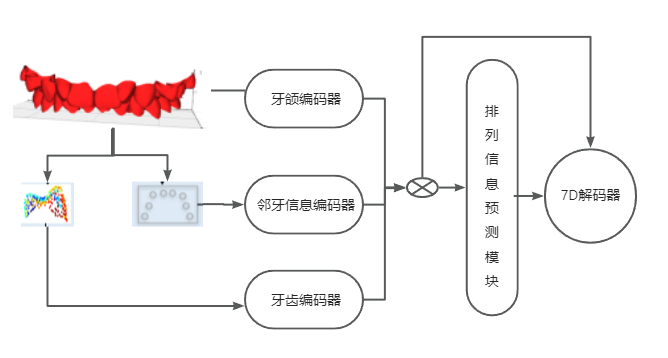
如图所示,我们提出的方法包括了两个主要阶段。首先是预处理阶段,从整个模型中分割出牙冠,然后对每个牙冠进行语义标注。第二阶段使用具有四个主要组件的网络来执行以下功能:
- 一组基于PointNet的点特征编码器,用于颌骨级和牙齿级的特征提取;
- 一个计算中心点之间距离信息编码器,其在牙齿之间传递信息;
- 排列预测模块用于组合其对应的牙齿级特征、全局特征和邻牙信息特征,并将组合结果作为输入,并且输出相对于该牙齿的输入位置的特征;
- 7D解码器,将预测特征解码成对应7D模块,其中包括3个特征用于位移,4个特征用于旋转。
预处理
- 计算牙颌全局点云得方差

; - 然后对于每颗牙齿随机采样512个点,并除以
,使得点云归一化,方便学习特征和收敛,- 获取(32,512,6)形状得特征,32指的32颗牙,512指的是512个点,6指的是6个特征,分别是点云坐标及法线。
- 切记不要减去均值,因为这样会让位移矢量难以学习;
- 获取每颗牙到目标位移及旋转差,其中位移差除以除以
,使得位移归一化,旋转差转换成四元数,因为四元数默认在[0,1]之间,无需归一化,且无死锁问题; - 增强处理:
- 将目标点云同样做处理,且学习目标为单位矩阵,即

,目的是学习正确位姿,且最好得位姿默认是从单位矩阵开始。
- 将目标点云同样做处理,且学习目标为单位矩阵,即
损失函数:
我们的观察是牙齿在治疗过程中几乎保持刚性,我们的网络特性在输入中保持每个牙齿的形状不变,基于我们的观察和我们的网络特性,且通过大量试验验证:
- 使用L1损失计算预测7d位姿与实际位姿的差;

,其中,表示
范数[^12]。
- 结论:可行
- 通过CD损失计算通过预测7d位姿旋转后的点云与目标点云的差;
- 结论:效果需1类似
- 通过EMD损失计算通过预测7d位姿旋转后的点云与目标点云的差;
- 结论:
- 通过联合计算预测后中心点与其他中心点的差与旋转矩阵的误差;
- 结论:会强制排列牙弓,不会造成某个牙乱飞
实验:
网络细节:
所有编码器特征维度在排列预测模块前被整合为256维度,排列预测模块用的128维度的LSTM进行排列预测,7D解码器最后一层用的Tanh激活函数,最后一层的权重被初始化为零,因为我们假设牙齿更有可能是不进行移动。
训练细节
我们在每颗牙齿上随机抽取512个点作为输入。至于缺牙,我们把它们的位置设置为0。为了增加训练的数据量,输入模型的所有单个牙齿,全部随机旋转一个角度,在我们的实验中角度范围在
之间,其平移距离范围在
,缩放范围在
。我们的网络是用PyTorch实现,并且在一个服务器的一个3090-Ti GPU 上训练,使用 Adam 优化器。batch size=24, learning rate=1.0e-3。
数据细节:
期望数据在500份。
- mesh_{编号} :用于存放正畸初始位(治疗前)的网格模型,每个牙牙齿顶点至少大于512;
- {编号}.json : 用于存放相关信息,包括以下:
- 治疗前到治疗后4*4变换矩阵,
- 缺失牙位号(方便定位处理)
- 牙齿颗数(方便遍历)
- 不可动牙齿牙位号(现阶段非必须)
- 矫正步数(现阶段非必须)
- 每步矫正4x4矩阵(现阶段非必须)
注意事项:
- 数据不能从同一份牙颌产生,须保持每一份数据特异性。
- 治疗后数据保证绝对性准确,即几乎无二义性判断。

