自动摘要: 工作交接文档 前言 本人在云甲工作一年零三个月,主要负责以下工作:数据标注,数据标注工具开发,算法部署,二维图像算法开发,参与椅旁软件开发。非常感谢公司给我这个机会,也感谢在整个工作过程中 ……..
工作交接文档
前言
本人在云甲工作一年零三个月,主要负责以下工作:数据标注,数据标注工具开发,算法部署,二维图像算法开发,参与椅旁软件开发。非常感谢公司给我这个机会,也感谢在整个工作过程中杨新组长的指导,使我从中受益良多。
工作成果
1.数据标注
在职期间所有数据均已存放在51服务器中
1.1 排牙
数据存放路径:\192.168.1.51\产品部\13 正畸模拟器验收订单\AI训练集
排牙数据详细情况见如下:
| 数据类型 | 数据量 |
|---|---|
| 正常牙训练数据 | 250 |
| 缺失牙训练数据(4、5号牙) | 1740 |
| 医生排牙数据 | 123 |
排牙数据详细记录文档
1.2 全冠
数据存放路径:\192.168.1.51\产品部\0_AI数据\AI冠训练数据
全冠数据详细情况如下:
| 牙齿编号 | 上颌 | 下颌 | 总计 |
|---|---|---|---|
| 4号牙 | 79 | 81 | 160 |
| 5号牙 | 129 | 88 | 217 |
| 6号牙 | 148 | 175 | 323 |
全冠数据详细记录文档
1.3 齿龈分离
数据存放路径:\192.168.1.51\产品部\0_齿龈分离
齿龈分离数据详细情况如下:
| 任务 | 数据量 |
|---|---|
| 齿龈分离(口扫) | 5431份 |
| 齿龈分离(模扫) | 3284份 |
1.4 数据自动标注
关于半自动标注数据请查看此文档
备注:1、口/模扫标注工具模型训练代码及使用方式;
代码位置:/home/liuhang/project/ultralytics
- 数据处理
# 1.激活环境
conda activate myyolov8
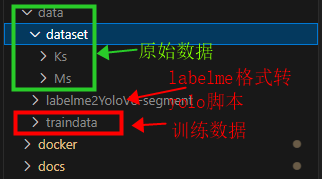
# 2.将labelme格式数据转换成yolo格式
cd data/labelme2YoloV8-segment/
python labelme2YoloV8-segment/convert_folder.py dataset/Ks traindata/Ks_tooth 0.8
(输入路径) (输出路径) (训练集占比)
训练
1.训练
nohup sh train.sh > log/logname.log 2>&1 &
2.预测
yolo task=segment mode=predict model=runs/segment/train/weights/best.pt source=data/traindata/ks_implant_abandon_tooth/images/val device=0
3.导出onnx
yolo task=segment mode=export model=runs/segment/train/weights/best.pt format=onnx
编写配置文件
在此基础上修改即可
type: yolov8_seg
name: yolov8x-seg-r20230620
display_name: YOLOv8x-Seg Ultralytics
model_path: ks-seg.onnx #训练的标注模型的名字
nms_threshold: 0.45
confidence_threshold: 0.25
classes: #有新增类别 请在下面添加- abandon
- tooth
- implant
更详细的内容,可查看
2、AI特征点标注工具代码:F:\Code\pyProject
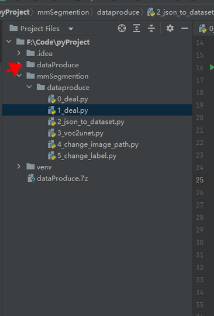
代码
1.齿龈分离(模扫)
背景:
口扫齿龈分离要求在cpu的推理环境下进行推理
目前支持的类别有tooth 和 implant
代码位置:服务器192.168.1.53
路径:/home/liuhang/project/PaddleSeg
结构详解:
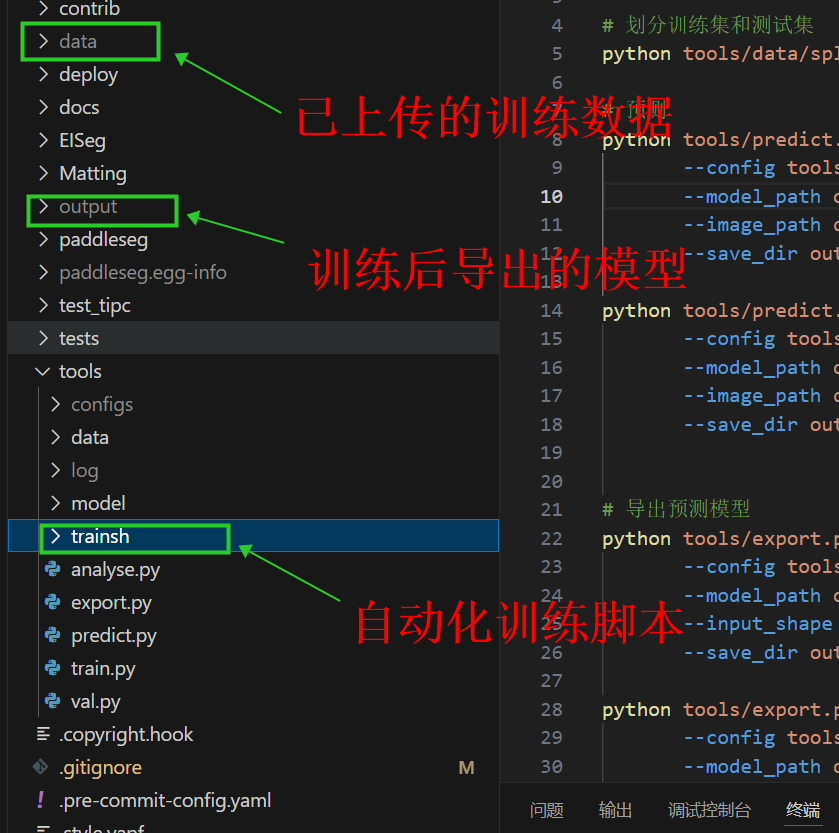
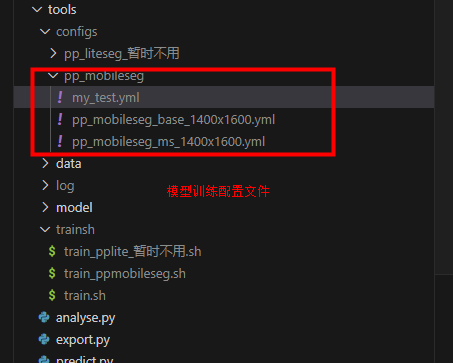
模扫齿龈分离选用paddlepaddleSeg框架中的ppmobileseg 网络进行训练,现在只区分牙齿区域,其余区域均不分割。准确率大致在97%左右。
如何使用:
# 1.激活对应环境
conda activate paddleseg
# 2.运行data路径下的数据预处理代码,整理数据
cd data
python dataProduce.py
# 3.将数据处理成训练格式
cd ..
python tools/data/labelme2seg.py data/dataset(输入) data/ms_tooth/(输出)
# 4.划分训练集与测试集
python tools/data/split_dataset_list.py data/ms_tooth images annotations --split 0.8 0.1 0.1 --format bmp png (图片格式 要求以后都提供bmp)
# TODO: 修改train_ppmobileseg.sh中的save_dir参数
# 5.训练
nohup sh tools/trainsh/train_ppmobileseg.sh > tools/log/ppmobileseg_7_29.log 2>&1 &
# 6.预测
python tools/predict.py \
--config tools/configs/pp_mobileseg/pp_mobileseg_ms_1400x1600.yml \
--model_path output/pp_mobileseg_tooth_7_29/best_model/model.pdparams \
--image_path data/1.bmp \
--save_dir output/result/pp_moble_7_29
# 7.导出预测模型
python tools/export.py \
--config tools/configs/pp_mobileseg/pp_mobileseg_ms_1400x1600.yml \
--model_path output/pp_mobileseg_tooth_7_29/best_model/model.pdparams \
--input_shape 1 3 512 640 \
--save_dir output/inference_model/ppmobileseg_tooth_7_29
# 8.导出onnx模型
paddle2onnx --model_dir output/inference_model/ppmobileseg_tooth_7_29 \
--model_filename model.pdmodel \
--params_filename model.pdiparams \
--opset_version 11 \
--save_file ppmobileseg.onnx
中断后训练
2.齿龈分离(口扫)
数据存放路径:\192.168.1.51\产品部\齿龈分离
代码位置:服务器192.168.1.53
路径:/home/liuhang/mmlab/mmsegmentation

齿龈分离(口扫)目前训练两个版本的模型:
第一种:种植杆,无关区域
第二种:种植杆,无关区域,牙齿
第一种效果尚可,第二种在添加完牙齿数据后,种植杆数据效果会变差准确率在92%左右。
使用方法:
- 数据预处理
找到本地数据预处理代码:F:\Code\pyProject
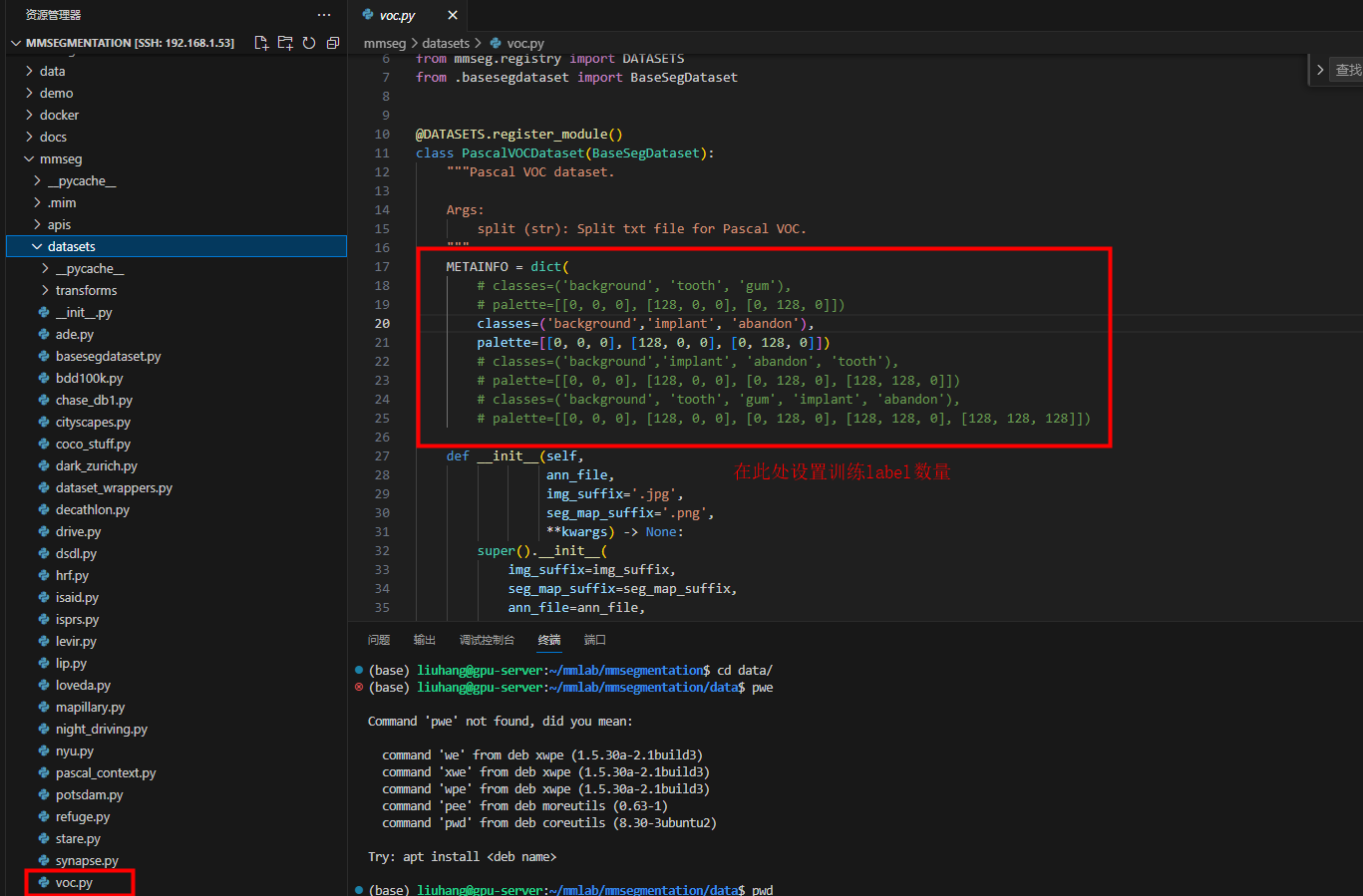
注意:新增label需要修改此处
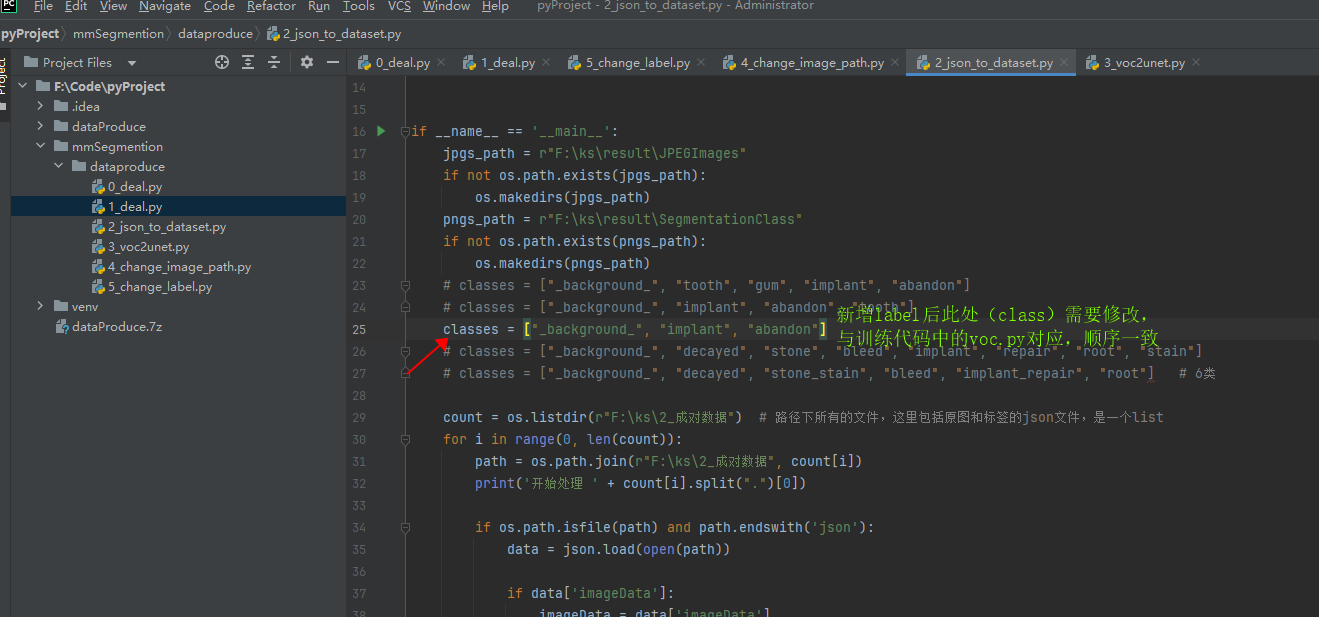
注意:这是部署代码里面的标签,classes中的标签顺序要与case顺序一致;训练代码中的****voc.py中同理
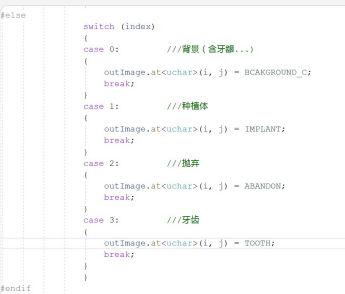
数据处理步骤
执行完毕后上传数据至:/home/liuhang/mmlab/mmsegmentation/data/tooth 路径下即可
- 训练前修改配置文件
共需修改两个配置文件
/home/liuhang/mmlab/mmsegmentation/mmseg/datasets/voc.py
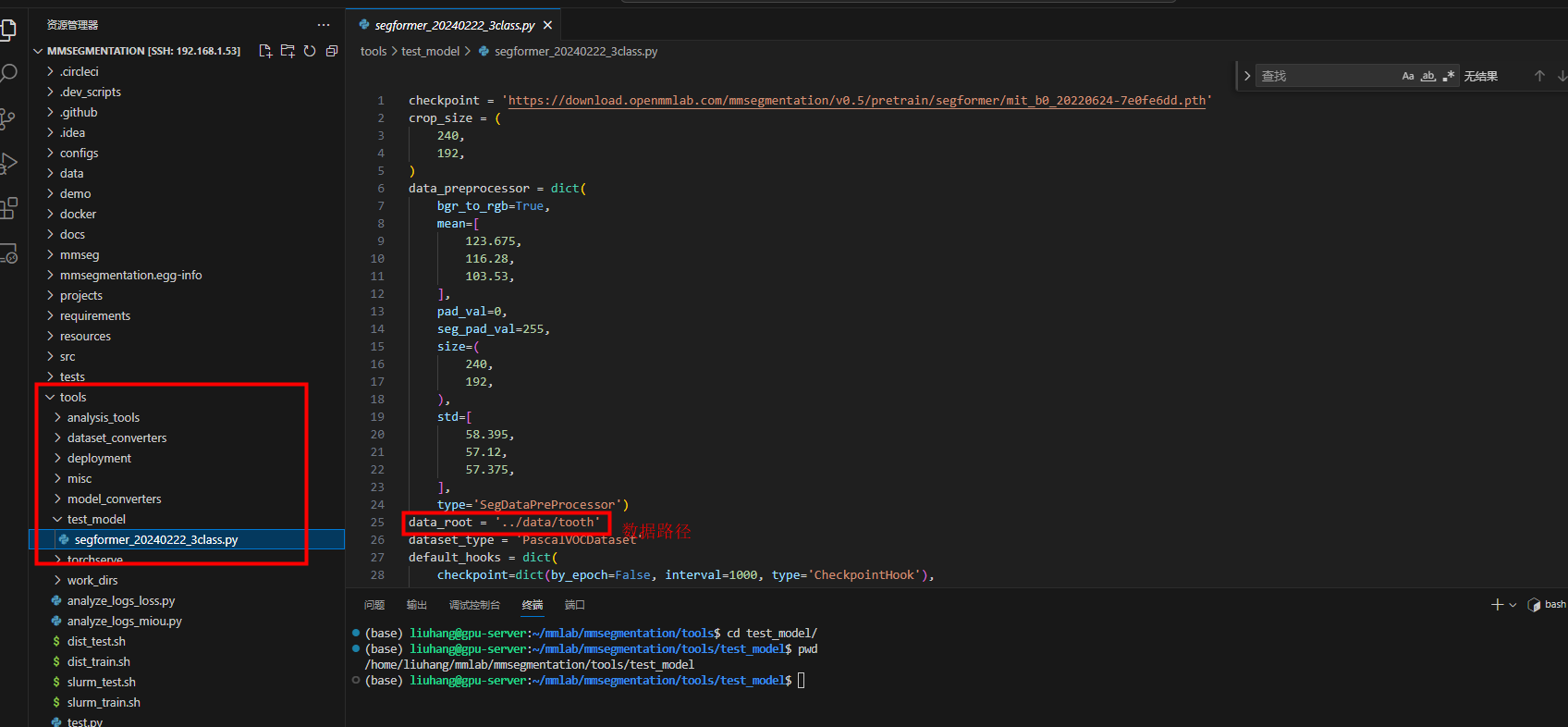
/home/liuhang/mmlab/mmsegmentation/tools/test_model/segformer_20240222_3class.py
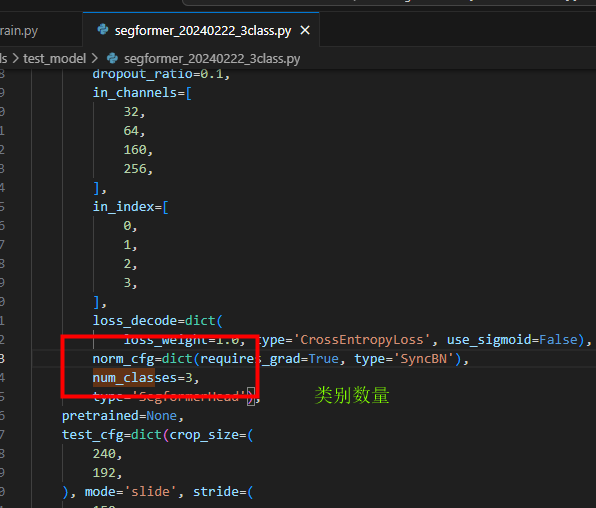
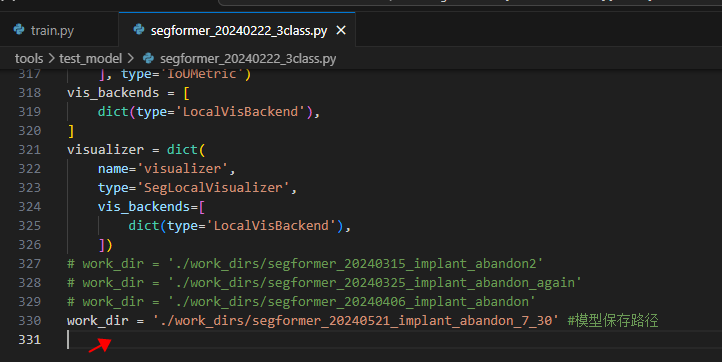
- 训练
运行/home/liuhang/mmlab/mmsegmentation/tools下的tarin.py
# 1.激活环境
conda activate myopenmmlab
# 2.开始训练
cd tools
python train.py
- 导出
/home/liuhang/mmlab/mmdeploy 打开当前项目
需要上传两个文件:
1.替换训练时所用的配置文件 :”segformer_20240222_3class.py”;
2.上传训练模型 “iter_100000.pth”
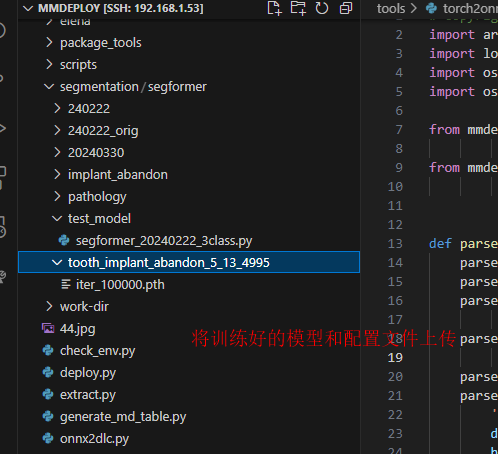
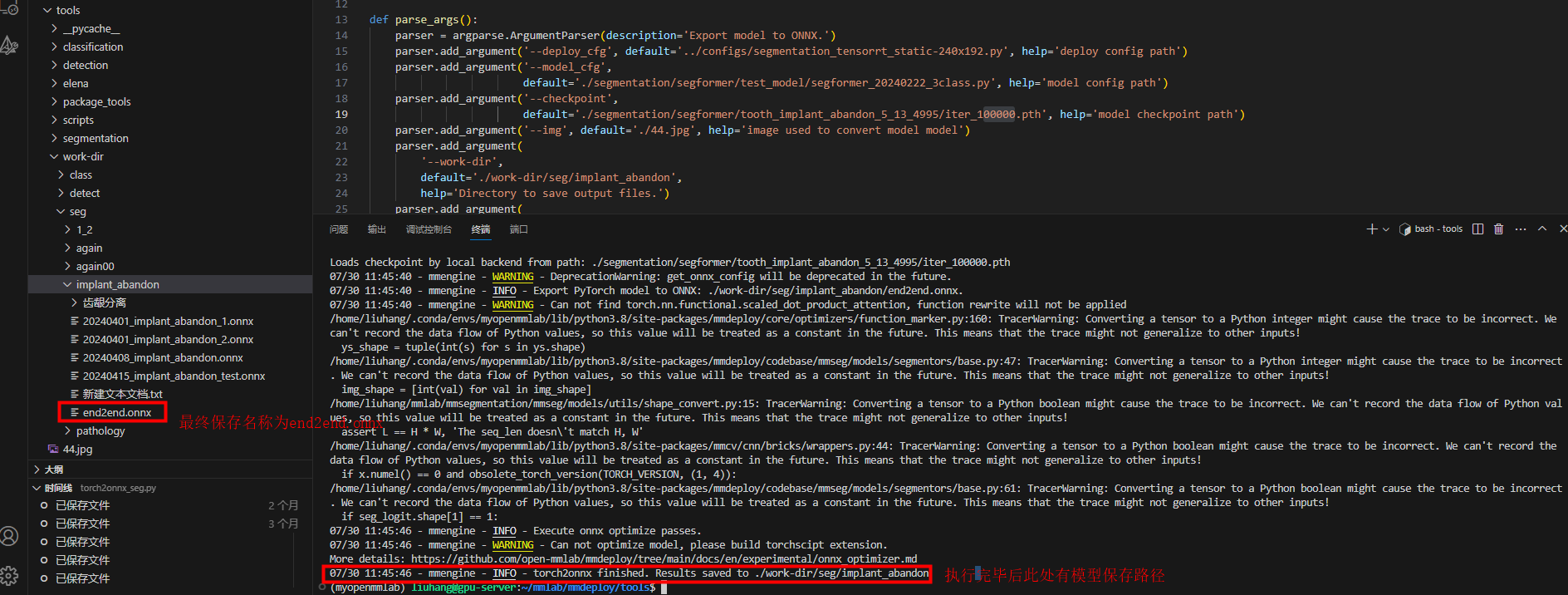
# 1.激活环境
conda activate myopenmmlab
# 2.转换模型
cd tools
python torch2onnx_seg.py
个人遗憾
本人作为部署工程师,其实一直想实现一个通用的算法部署框架,即一套代码部署所有算法二维三维均可兼容,每个算法封装成单独的element,后续根据具体的业务需求,能够将多个element组合成对应的业务pipline。但由本人实现算法有限,目前仅封装了齿龈分离的element。齿龈分离的部署代码就是依据这种结构进行开发目前暂命名为AI2Dlibrary。
团队期望
作为一名部署工程师我还是期望团队能有自己的部署框架,且要将业务端和部署端分离,其次就是希望团队内多一些技术分享会,大家可以交流沟通一些自己探索的技术,来拓宽眼界和技术栈。

