自动摘要: 摘要: 三维牙齿分割是数字正畸学的一项重要任务。已经提出了几种深度学习方法用于从三维牙科模型或口内扫描中自动分割牙齿。这些方法需要注释的3D口内扫描。手动注释3D口内扫描是一项艰巨的任务。 ……..
摘要:
三维牙齿分割是数字正畸学的一项重要任务。已经提出了几种深度学习方法用于从三维牙科模型或口内扫描中自动分割牙齿。这些方法需要注释的3D 口内扫描。手动注释3D 口内扫描是一项艰巨的任务。一种方法是设计自我监督的方法,以减少人工标签的努力。与场景点云、形状点云等其他类型的点云数据相比,三维齿点云数据具有非常规则的结构和较强的形状优先性。我们看看有多少代表性的信息可以从一个单一的三维口腔内扫描学习。我们采用十种不同的方法对其进行定量评价,其中六种是通用的点云分割方法,另外四种是特定的牙齿分割方法。令人惊讶的是,我们发现,通过单个3D 口腔内扫描训练,Dice 得分可以高达0.86,而完整的训练集给出的 Dice 得分为0.94。结果表明,在适当的条件下,如数据增强,分割方法可以从单个三维齿点云扫描中获得大量的信息。我们是第一个从一个单一的三维口腔扫描定量评估和证明深度学习方法的表征学习能力。这可以通过尽可能充分地利用现有数据,在极端数据限制情况下建立牙齿分割的自我监督方法。 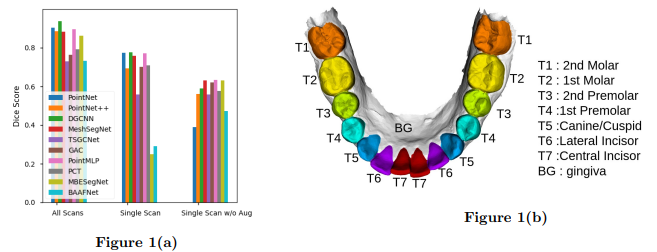
图1. 单扫描表征学习: 我们表明,几种深度学习方法可以训练(a)使用一个单一的三维口内扫描,如此图像(b)在适当的条件下。
关键词:
三维牙齿分割,牙齿点云,牙齿网格,口内扫描分割,三维牙齿模型,深度学习,机器学习,单一图像学习
1. 前言
口腔内扫描仪(IOS)由于其快速重建三维表面的能力,正日益成为数字牙科不可或缺的一部分。这些相机被广泛用于代替传统的口腔内或牙科相机。虽然使用牙科相机拍摄每颗牙齿的照片可能需要几个小时,但口内扫描仪可以在几分钟内完成扫描。这些三维口腔内扫描或三维牙科模型可以捕捉三维形态,拓扑和颜色信息的形式点云或网格。口腔三维扫描可以辅助牙齿矫正设计、修复设计、微笑美容等。自动三维齿点云分割是所有这些步骤中的关键一步。
近年来,基于多种深度学习的方法被提出用于口腔三维扫描中的牙齿自动分割。我们注意到,这些方法1-9中的大多数都是完全监督的,只有少数是弱监督或半监督的。提出了一种利用点网络相似网络从齿点云中学习全局信息,利用不同尺度的邻接矩阵学习局部信息的网格网络。张等人。提出了一种利用并行网络分别学习坐标和法线信息的方法。等等。Al10提出了一种方法,该方法利用下颌上的牙齿具有对称结构的事实,并在连接牙齿质心的曲线之前强加一个形状。这些方法使用带注释的3D 口内扫描(从802到400010)进行训练。手动注释3D 口内扫描是一个乏味的过程。此外,近年来自我监督方法在机器学习领域得到了越来越多的关注。自我监督技术有了很大的进步。在自我监督中,借口任务是自动构建的,不需要任何手动注释的数据,这使网络能够学习有用的功能,并利用这些知识在下游任务产生令人印象深刻的结果,即使有限的数据。尽管自然图像中的自我监控有很大的好处,而且三维点云如场景点云、形状点云等也有很大的好处,但是在口内扫描的三维牙齿分割中缺乏自我监控的方法。自我监督允许我们从有限的数据中学习。正是在这种情况下,我们调查的代表性权力的单一口腔内扫描。这是一个很重要的问题,因为不同于自然图像更加多样化,牙齿扫描有非常强大的形状和大小之前-例如,通常下颌有对称排列的牙齿和牙齿有相对的大小约束,例如一个臼齿可能不会比门牙体积小,有两个例子的牙齿在两侧的下颌等。知道我们可以在监督下从一个单一的口腔内扫描中提取多少信息来进行3D 牙齿分割可以作为自我监督的基线,也就是说,网络将能够通过自我监督学到最小限度的信息。
我们包括十种不同的方法来评估单次口内扫描的代表性能力。我们精心挑选了通用的点云分割方法和齿点云分割方法。此选择背后的基本原理是确保分析可以在不同方法之间推广。我们选择一般分割方法的原因是,虽然技术上,牙点云分割方法也操作点云,牙点云与场景点云几乎没有什么不同,因为大多数牙点云分割方法实际上操作牙齿网格数据,但它表示为点云数据,我们将在后面的2.1节中看到。我们的工作组织如下: 首先描述了数据集,其预处理,数据增强方法,然后介绍和概述了不同的通用和齿特异点云分割方法。接下来,我们提供了我们进行的实验和结果的细节。最后,我们对研究结果及其相关性进行了简要的讨论。
2. 方法
2.1 数据处理
我们有一个由50个实验对象组成的私人数据库。该数据集包括受试者下颌的3D 口内扫描。原始的口内扫描包括超过100000个网格。我们使用二次下采样的方法将网格下采样到16000个网格,以便保留原始口内扫描的拓扑结构。在下采样之后,每个网格单元用24维向量描述,其中坐标为12维,法线为剩余的12维。坐标由三角形网格的三个顶点和网格的重心组成,而法线对应于四个坐标点上的法线。所有3D 牙科模型或口腔内扫描的地面真相注释(autodesk MeshMixer)是根据临床要求并在我们的合作伙伴组织的专业牙医的建议下完成的。注释的3D 口腔内扫描的示例如图1所示。每次扫描最多有14颗牙齿(牙齿计数分布如表1所示)
表1. 跨数据分割的牙齿计数分布
2.2 数据增强
为了提高模型的泛化能力,通过组合1)随机旋转,2)随机平移和3)在合理范围内对每个3D 牙齿表面进行随机重新缩放(例如放大/缩小)来增加数据的训练集和验证集。具体而言,沿着3D 空间中的三个轴中的每一个,训练/验证表面具有50% 的移位和缩放概率,分别在 [ -10, 10] 和 [0.8, 1.2] 之间均匀采样。此外,每个训练/验证表面有50% 的概率是 x 轴和 y 轴和 z 轴旋转,角度均匀采样在[ -π,π ]之间。这些随机操作的组合模拟了来自每个原始表面的40个“新”病例。
2.3 分割方法
2.3.1 一般点云分割方法
在本节中,我们将研究一般的点云分割方法。我们所说的“一般”是指分割方法与场景点云、激光雷达点云或形状点云等点云数据的类型无关。
PointNet11 - 它是一个高效的基于深度学习的网络架构,用于点云处理任务,如对象分类、部分分割、场景语义解析等。PointNet 体系结构很好地理解了点云的全局特性。
PointNet + +12 - Qi 等人引入了与 PointNet 体系结构一起的分层特征学习,从而能够更好地理解点云中的局部邻域。
DGCNN13 - 这项工作介绍了一种网络架构,用于从点云捕获拓扑信息。由于点云本质上是一组无序的点集,它们缺乏拓扑信息。DGCNN 提出了一种称为 EdgeConv 的网络模块,该模块可以应用于网络不同层次的动态计算图。EdgeConv 还捕获当地的邻里信息。
PointMLP14 - Ma等人结果表明,点云的纯剩余网络结构可以在不降低网络速度的情况下实现高度竞争性的性能,而且具有昂贵和复杂的局部几何提取器/分析器。
PCT15 - 遵循变压器架构在自然语言处理和自然图像处理方面的巨大成功,Guo 等人提出了一种用于点云处理的变压器网络。该算法精心设计了一个输入网络,采用了最远点采样和最近邻搜索,使网络既受益于点云的局部结构,又受益于点云的全局结构。
BAAFNet16 - Qiu等人。提出了一种网络体系结构,通过结合几何和语义特征的双边方式提取局部上下文细节。它们还处理点云的不同分辨率,从而减少了模糊性,并全面解释了点云每个点的不同之处。
2.3.2 牙齿点云分割方法
在这一部分中,我们将看一看专门为牙齿分割而设计的方法。我们还将说明这些方法是如何受到一般点云分割方法的影响。
MeshSegNet1 - Lien 等人提出了一种新的网络结构,其中图形约束的学习模块以分层方式提取多尺度上下文特征,然后密集同化局部到全局的几何特征为一个全面的角色塑造的牙齿网格细胞的分割任务。这个网络大量借鉴了 pointnet 体系结构,但在理解局部几何学时使用了邻接矩阵。
GAC3 - Zhao 等人提出了一种网络体系结构,该体系结构使用两个分支来提取细粒度的局部信息和全局信息。全局特性分支在概念上类似于 PointNet 体系结构。本地信息提取器分支引入了一个名为 LSAM 的模块。该模块从 DGCNN 体系结构中借鉴了 EdgeConv 的概念,它学习动态计算图的边权重,同时通过使用位置和语义特征进行局部上下文学习。图注意机制用于总结从动态图中获得的信息。
TSGCNet2 - Zhang 等人提出了一个两流网络,其中两个独立的流专门用于理解坐标和点法线。该方法与 GAC 方法有一个共同点,都是利用图注意层来总结图的权重信息。但是它区分了不同类型的信息,比如坐标和法线,最初应该单独处理,以充分利用它们来表征网格单元。
MBESegNet4 - Li 等人提出了一种能够处理分层和多尺度信息的网络。与 BAAFNet16 中的概念相似,这种方法也用几何和语义信息来双向增强局部特征。
3. 实验
任务是从3D 牙齿模型中分割牙齿,C = 8个不同的语义部分,表示中切牙(T7) ,侧切牙(T6) ,犬齿/尖牙(T5) ,第一前磨牙(T4) ,第二前磨牙(T3) ,第一磨牙(T2) ,第二磨牙(T1)和背景/牙龈(BG)。所有的实验都是在监督下进行的。
3.1 实验设置 1(所有扫描)
对于这个实验,我们使用 32:8:10 的 train-test-val 分割来划分数据集。利用前面描述的数据增强方法对训练集和验证集进行了增强。所有的十种分割方法都是在这个完整的数据集上以完全监督的方式进行训练的。我们的数据集包括牙齿缺失、错位、断牙等情况。
3.2 实验设置 2(单次扫描)
在这种情况下,我们只使用一个数据点或口内扫描的32个受试者在实验设置1的训练集进行训练。测试和验证集与实验设置1相同。在实验设置1中,增加了训练集和验证集。已经选择的口内扫描上有14颗牙齿。
3.3 实验设置3(单扫描 w/o 增强)
这类似于实验设置2,但是没有使用数据增强。在这种情况下,相同的样本被重复多次以匹配培训的批量大小。
3.4 指标
我们使用四种不同的指标来衡量牙齿分割方法的性能。这些指标是整体准确度(OA) ,骰子评分(DSC) ,灵敏度(SEN)和正预测值(PPV)。对于所有的指标,我们采用所有类的平均值。
3.5 训练结果
实验已经进行了400个纪元,选择了最佳验证模型。所有的模型都已经在 RTX 8000系统上进行了训练。
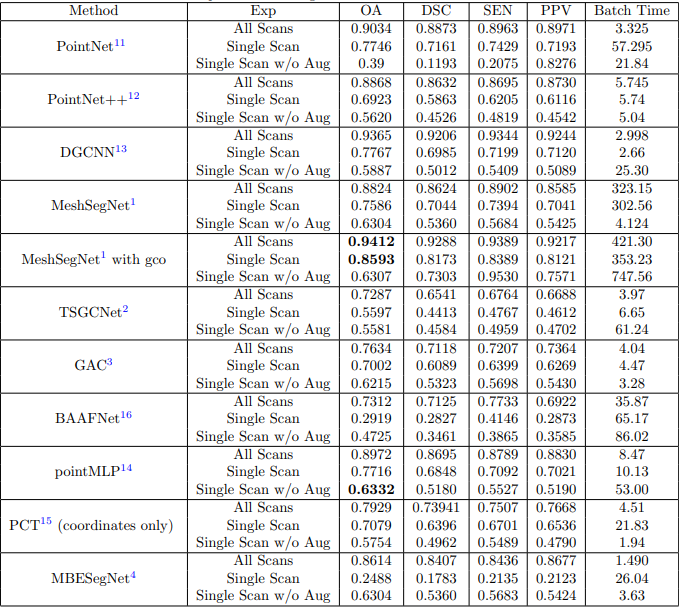
表2. 牙齿分割的结果,从这10种不同的方法在整体准确度和Dice评分。每个实验设置下的最佳结果以粗体列出。
4. 实验结果
我们的实验结果列在表2和表3中。表2显示了在前面描述的三种不同的实验设置(全扫描、单扫描和单扫描增强)下,所有类别标签的不同方法的平均 Dice 评分、灵敏度和阳性预测值的整体准确度。图1(a)显示了不同设置下不同方法的 Dice 得分比较
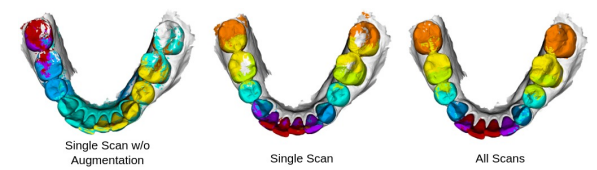
图2. DGCNN 牙齿标记方法在全扫描、单扫描和单扫描增强训练中的定性比较
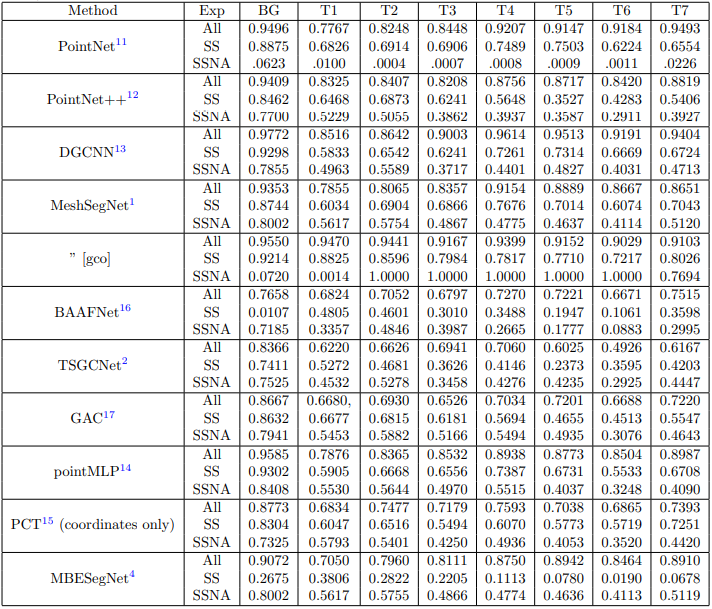
表3. 对十种方法进行了分割。所有扫描、 SS (单次扫描)和 SSNA (单次扫描增强)分别表示实验设置1、2和3
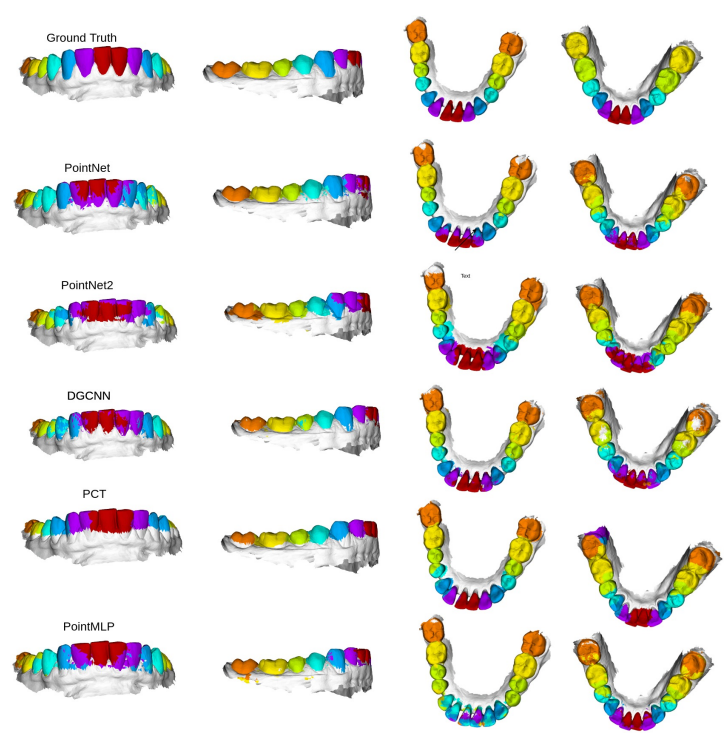
图3. 通过单次扫描训练的不同方法进行牙齿标记的比较

图4. 通过单次扫描训练的不同方法进行牙齿标记的比较
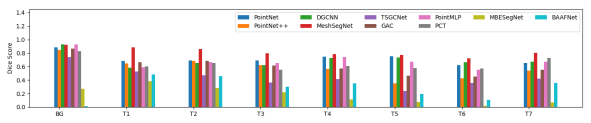
图5. 通过单次扫描训练的不同方法获得的牙向 Dice 评分
表3和图5显示了10种不同方法在不同类别标签上的性能比较。通过单次扫描训练的不同方法进行牙齿标记的定性结果如图3和图4所示。对于 MeshSegNet1,我们包含了两个不同的结果-一个带有图切割后处理(gco) ,另一个没有后处理。我们观察到图割后处理作为一个可插入的模块可以驱动 Dice 得分更高,但是代价是额外的计算能力。在实验中我们还注意到了数据增强的效果。表3和图5显示了10种不同方法在不同类别标签上的性能比较。通过单次扫描训练的不同方法进行牙齿标记的定性结果如图3和图4所示。对于 MeshSegNet1,我们包含了两个不同的结果-一个带有图切割后处理(gco) ,另一个没有后处理。我们观察到图割后处理作为一个可插入的模块可以驱动 Dice 得分更高,但是代价是额外的计算能力。在实验中我们还注意到了数据增强的效果。除 BAAFNet 和 MBESegNet 方法外,其余方法均通过数据增强得到改进。这种异常可能归因于这样一个事实,即牙齿网格被视为齿点云,其中三个顶点的坐标被视为特征,从牙齿网格三角形中心预测这些可能是具有挑战性的。值得注意的是,即使不使用任何后处理,如图形切割(MeshSegNet) ,方法,如 DGCNN,PointNet,MeshSegNet 和 PointMLP 达到0.77骰子得分。数据增强似乎混淆了 BAAFNet 和 MBESegNet 网络。需要指出的是,在提交这项工作时,TSGCNet、 GAC 和 MBESegNet 的实现尚未公开,因此我们实施了这些方法。有趣的是,当不使用数据增强时,PointNet 在单次扫描学习方面表现最差。它根本不会学到任何信息。图2显示了在不同的实验设置下通过 DGCNN 方法进行的口内扫描标记的样本。样本的门牙标签分配到磨牙。这可能是由于缺乏随机旋转数据增强,DGCNN 的学习是基于输入单扫描的方向,它已被训练。PCT 方法只在坐标上而不是法线上进行训练,但是在单次扫描设置中成功地获得了良好的性能。BAAFNet 的单次扫描训练提出了一个有趣的例子,即错误标记的细胞不局限于一个区域。相反,他们是分散的。这可能是由于 BAAFNet 从牙齿网格的原始分辨率创建了多个分辨率,但是与网格单元相关的三角形顶点(和法线)不会改变以适应下采样。
5. 论述
我们的工作量化地建立了从一个单一的三维口腔内扫描中可以学习到大量信息的可能性。这可以作为在极其有限的数据注释场景下设计自我监督方法的起点。此外,研究结果也提出了一些有趣的问题。我们知道基于深度学习的方法依赖于大量的数据,一般的理解是数据越多,结果越好。但是目前的结果迫使我们在牙齿分割的背景下思考: 我们真的需要那么多的数据吗?或者仅仅是代表性的口内扫描就足够了。3D 口腔内扫描对牙齿分割的挑战,通常被理解为: 错位的牙齿、缺失的牙齿、破损的牙齿、牙冠等。在这种情况下,如果我们以口内扫描的形式表示每个挑战,模型的性能是否仍然很高?牙齿分割的另一个挑战是,不是所有的受试者都有所有的牙齿,例如,孩子的牙龈上可能有12颗牙齿。这可能会因为将 T1与 T2混淆而导致网络问题。但是如果我们观察一个包含14颗牙齿的口内扫描,理论上,可以从这些扫描中生成12颗牙齿的口内扫描,然后使用形状完成方法进行训练?此外,我们可以很容易地观察到,牙齿分割是在交叉的部分分割和实例分割问题。自然而然地,问题就出现了,为什么不注释一半的口内扫描包含每个牙齿的一个实例,而不是整个?或者我们可以把这个问题转化为更通用的点云领域,通过问,是否有必要注释整个对象,如果它是对称的性质?我们最后说,我们的工作为未来的探索开辟了许多有趣的途径,通过建立定量的结果,什么可以从一个单一的口内扫描学习。

